Understanding PEB and Ldr structures represents a starting point when we are dealing with API hashing. However, before proceeding to analyze a sample it’s always necessary to recover obfuscated, encrypted or hashed data. Because of that, through this blogpost I would like to continue what I have started in the previous post, using emulation to create a rainbow table for LummaStealer and then write a little resolver script that is going to use the information extracted to resolve all hashes.
💡It’s worth mentioning that I’m trying to create self-contained posts. Of course, previous information will give a more comprehensive understanding of the whole process, however, the goal for this post is to have a guide that could be applied overtime even on different samples not related to LummaStealer.
Resolving Hashes
Starting from where we left in the last post, we could explore the function routine that is in charge of collecting function names from a DLL and then perform a hashing algorithm to find a match with the input name.
Figure 1: LummaStealer API Hashing overview
At the first glance, this function could be disorienting, however, understanding that ecx contains the module BaseAddress (explained in the previous article) it is possible to set a comment that is going to make the whole function easier to understand. Moreover, it has been also divided in three main parts( first two are going to be detailed in the next sections):
Collecting exported function within a PE file;
Hashing routine;
Compare hashing result until a match is found, otherwise return 0; (skipped because of a simple comparing routine)
Collecting exported function within a PE file
The first box starts with the instruction mov edi, ecx where ecx is a BaseAddress of a module that is going to be analyzed. This is a fundamental instruction that gives us a chance to infere the subsequent value of edi and ebx. In fact, if we rename values associated to these registers, it should be clear that this code is going to collect exported functions names through AddressOfNames and AddressOfNameOrdinals pointers.
Figure 2: Resolving structures names
Those structures are very important in order to understand what is happening in the code. For now, you could think about those structures as support structures that could be chained together in order to collect the actual function pointer (after a match is found!) within the Address of a Function structure.
💡 At the end of this article I created a dedicated sections to explain those structures and their connections.
Another step that could misleading is related to the following instruction:
where ebx becomes a pointer for IMAGE_EXPORT_DIRECTORY.
In order to explain this instruction its useful to have a look at IMAGE_OPTIONAL_HEADERS documentation, where Microsoft states that DataDirectory is pointer to a dedicated structure called IMAGE_DATA_DIRECTORY that could be addressed through a number.
With that information let’s do some math unveiling the magic behind this assignment.
eax corresponds to the IMAGE_NT_HEADERS (because of its previous assignment)
From there we have a 0x78 offset to sum. If we sum the first 18 bytes from eax, it’s possible to jump to the IMAGE_OPTIONAL_HEADER. Using the 60 bytes remaining to reach the next field within this structure, we could see that we are directly pointing to DataDirectory.
From here, we don’t have additional bytes to sum, it means that we are pointing to the first structure pointed by DataDirectory, that is, according to the documentation the IMAGE_DIRECTORY_ENTRY_EXPORT also known as Export Directory.
💡 See Reference section to find out a more clear image about the whole PE structure
Retrieve the function pointer
Once the code in charge to collect and compare exported functions has been completed, and a match is found, it’s time to retrieve the actual function pointer using some of the structures mentioned above. In fact, as you can see from the code related to the third box (that has been renamed accordingly), once the match if found, the structure AddressOfNameOrdinals it’s used to retrieve the functions number that is going to address the structure AddressOfFunctions that contains the actual function pointers.
Figure 3: Collect the actual function pointer
💡I don’t want to bother you with so much details at this point, since we have already analyzed throughly some structures and we still have additional contents to discuss. However, the image above has been thought to be self-contained. That said, to not get lost please remember that edi represents the Ldr_Module.BaseAddress
Analyze the hashing routine
Through the information collected so far, this code should be childishly simple.
ecx contains the hash name extracted from the export table that is going to forward as input to the hash function (identified, in this case, as murmur2). The function itself is quite long but does not take too much time to be understood and reimplemented. However, the purpose of this article is to emulate this code in order to find out the values of all hardcoded hashes.
Figure 4: MurMur2 hashing routine
As we have already done, we could select the function opcodes (without the return instruction) and put them in our code emulator routine. It’s worth mentioning that, ecx contains the function name that is going to be used as argument for hashing routine, because of that, it’s important to assign that register properly.
Let’s take a test. Using the LoadLibraryW name, we get back 0xab87776c. If we explore a little bit our code, we will find almost immediately this value! it is called each time a new hash needs to be resolved.
Figure 5: LoadLibraryW Hash
This behavior is a clear indication that before proceeding to extract exported functions, we need to load the associated library (DLL) in memory. With that information we could be sure that our emulator works fine.
Build a rainbow table
Building a rainbow table can be done in a few lines of code:
filter = ['ntdll.dll']
def get_all_export_function_from_dlls():
exported_func = {}
for dirpath, dirnames, filenames in os.walk("C:\\Windows\\System32"):
for filename in [f for f in filenames if f in filter]:
path_to_dll = os.path.join(dirpath, filename)
pe = pefile.PE(path_to_dll)
for export in pe.DIRECTORY_ENTRY_EXPORT.symbols:
if not export.name:
continue
else:
exported_func[hex(MurMurHash2(export.name))] = export.name
return exported_func
Python
The code presented above should be pretty clear, however, I would like to point out the role of the filter variable. Emulation brings a lot of advantages to reverse engineering, nevertheless, it also has a drawback related to performance. In fact, code that contains an emulation routine could be tremendously slow, and if you don’t pay attention it could take forever. Using a filter variable keeps our code more flexible, resolving tailored functions names without wasting time.
💡Of course, in this case we could look for libraries names used within the code. However, we could not be so lucky in the future. Because of that, I prefer to show a way that could be used in multiple situations.
Automation
Now that we have built almost all fundamental components, it’s time to combine everything in a single and effective script file. What we are still missing is a regular expression that is going to look for hashes and forward them to the MurMur2 emulator.
Observing the code, an easy pattern to follow involves a register and an immediate values:
mov REG, IMM
NASM
Implementing this strategy and filtering results only on kernel32.dll, we are able to extract all referenced hashes:
Figure 6: Some hashes related to Kernel32.dll
Conclusion
As always, going deep in each section requires an entire course and at the moment it’s an impossible challenge. However, through this blog post I tried to scratch the surface giving some essential concepts (that could be applied straightaway) to make reversing time a lot more fun.
Another important thing to highlight here, is related to combine emulation and scripting techniques. Emulation is great, however, writing a script that contains some emulated routine could be a challenging task if we think about efficiency. Writing a single script for a single sample its not a big deal and it won’t have a great impact in a single analysis, however, doing it a scale is a different kettle of fish.
That said, it’s time to conclude, otherwise, even reading this post could be a challenging task! 🙂
Have fun and keep reversing!
Bonus
In order to understand how API Hashing works it’s very useful to make your hand dirty on low level components. However, once you have some experience, it is also very helpful to have some tools that speed up your analysis. An amazing project is HashDB maintained by OALabs. It is a simple and effective plugin for IDA and Binary Ninja that is going to resolve hashes, if the routine is implemented. If you want to try out this plugin for this LummaStealer sample, my pull request has already been merged 😉
Appendix 1 – AddressOfNames
The algorithm to retrieve the RVA associated to a function is quite straightforward:
Iterate over the AddressOfNames structures.
Once you find a match with a specific function, suppose at i position, the loader is going to use index i to address the structure AddressOfNamesOrdinals.
k = AddressOfNamesOrdinals[i]
After collecting the value stored in AddressOfNamesOrdinals (2.a) we could use that value to address AddressOfFunctions, collecting the actual RVA of the function we were looking for.
function_rva = AddressOfFunctions[k]
Figure 7: How to retrieve functions names and pointers
💡If you want to experiment a little bit more with this concept, I suggest to take the kernel32.dll library and follows this algorithm using PE-Bear
Taurus Stealer, also known as Taurus or Taurus Project, is a C/C++ information stealing malware that has been in the wild since April 2020. The initial attack vector usually starts with a malspam campaign that distributes a malicious attachment, although it has also been seen being delivered by the Fallout Exploit Kit. It has many similarities with Predator The Thief at different levels (load of initial configuration, similar obfuscation techniques, functionalities, overall execution flow, etc.) and this is why this threat is sometimes misclassified by Sandboxes and security products. However, it is worth mentioning that Taurus Stealer has gone through multiple updates in a short period and is actively being used in the wild. Most of the changes from earlier Taurus Stealer versions are related to the networking functionality of the malware, although other changes in the obfuscation methods have been made. In the following pages, we will analyze in-depth how this new Taurus Stealer version works and compare its main changes with previous implementations of the malware.
Underground information
The malware appears to have been developed by the author that created Predator The Thief, “Alexuiop1337”, as it was promoted on their Telegram channel and Russian-language underground forums, though they claimed it has no connection to Taurus. Taurus Stealer is advertised by the threat actor “Taurus Seller” (sometimes under the alias “Taurus_Seller”), who has a presence on a variety of Russian-language underground forums where this threat is primarily sold. The following figure shows an example of this threat actor in their post on one of the said forums:
Figure 1. Taurus Seller post in underground forums selling Taurus Stealer
The initial description of the ad (translated by Google) says:
Stiller is written in C ++ (c ++ 17), has no dependencies (.NET Framework / CRT, etc.).
The traffic between the panel and the build is encrypted each time with a unique key.
Support for one backup domain (specified when requesting a build).
Weight: 250 KB (without obfuscation 130 KB).
The build does not work in the CIS countries.
Taurus Stealer sales began in April 2020. The malware is inexpensive and easily acquirable. Its price has fluctuated somewhat since its debut. It also offers temporal discounts (20% discount on the eve of the new year 2021, for example). At the time of writing this analysis, the prices are:
Concept
Price
License Cost – (lifetime)
150 $
Upgrade Cost
0 $
Table 1. Taurus Stealer prices at the time writing this analysis
The group has on at least one occasion given prior clients the upgraded version of the malware for free. As of January 21, 2021, the group only accepts payment in the privacy-centric cryptocurrency Monero. The seller also explains that the license will be lost forever if any of these rules are violated (ad translated by Google):
It is forbidden to scan the build on VirusTotal and similar merging scanners
It is forbidden to distribute and test a build without a crypt
It is forbidden to transfer project files to third parties
It is forbidden to insult the project, customers, seller, coder
This explains why most of Taurus Stealer samples found come packed.
Packer
The malware that is going to be analyzed during these lines comes from the packed sample 2fae828f5ad2d703f5adfacde1d21a1693510754e5871768aea159bbc6ad9775, which we had successfully detected and classified as Taurus Stealer. However, it showed some different behavior and networking activity, which suggested a new version of the malware had been developed. The first component of the sample is the Packer. This is the outer layer of Taurus Stealer and its goal is to hide the malicious payload and transfer execution to it in runtime. In this case, it will accomplish its purpose without the need to create another process in the system. The packer is written in C++ and its architecture consists of 3 different layers, we will describe here the steps the malware takes to execute the payload through these different stages and the techniques used to and slow-down analysis.
Layer 1 The first layer of the Packer makes use of junk code and useless loops to avoid analysis and prevent detonation in automated analysis systems. In the end, it will be responsible for executing the following essential tasks:
Allocating space for the Shellcode in the process’s address space
Writing the encrypted Shellcode in this newly allocated space.
Decrypting the Shellcode
Transferring execution to the Shellcode
The initial WinMain() method acts as a wrapper using junk code to finally call the actual “main” procedure. Memory for the Shellcode is reserved using VirtualAlloc and its size appears hardcoded and obfuscated using an ADD instruction. The pages are reserved with read, write and execute permissions (PAGE_EXECUTE_READWRITE).
Figure 3. Memory allocation for the Shellcode
We can find the use of junk code almost anywhere in this first layer, as well as useless long loops that may prevent the sample from detonating if it is being emulated or analyzed in simple dynamic analysis Sandboxes. The next step is to load the Shellcode in the allocated space. The packer also has some hardcoded offsets pointing to the encrypted Shellcode and copies it in a loop, byte for byte. The following figure shows the core logic of this layer. The red boxes show junk code whilst the green boxes show the main functionality to get to the next layer.
Figure 4. Core functionality of the first layer
The Shellcode is decrypted using a 32 byte key in blocks of 8 bytes. The decryption algorithm uses this key and the encrypted block to perform arithmetic and byte-shift operations using XOR, ADD, SUB, SHL and SHR. Once the Shellcode is ready, it transfers the execution to it using JMP EAX, which leads us to the second layer.
Figure 5. Layer 1 transferring execution to next layer
Layer 2 Layer 2 is a Shellcode with the ultimate task of decrypting another layer. This is not a straightforward process, an overview of which can be summarized in the following points:
Shellcode starts in a wrapper function that calls the main procedure.
Resolve LoadLibraryA and GetProcAddress from kernel32.dll
Load pointers to .dll functions
Decrypt layer 3
Allocate decrypted layer
Transfer execution using JMP
Finding DLLs and Functions This layer will use the TIB (Thread Information Block) to find the PEB (Process Environment Block) structure, which holds a pointer to a PEB_LDR_DATA structure. This structure contains information about all the loaded modules in the current process. More precisely, it traverses the InLoadOrderModuleList and gets the BaseDllName from every loaded module, hashes it with a custom hashing function and compares it with the respective “kernel32.dll” hash.
Figure 6. Traversing InLoadOrderModuleList and hashing BaseDllName.Buffer to find kernel32.dll
Once it finds “kernel32.dll” in this doubly linked list, it gets its DllBase address and loads the Export Table. It will then use the AddressOfNames and AddressOfNameOrdinals lists to find the procedure it needs. It uses the same technique by checking for the respective “LoadLibraryA” and “GetProcAddress” hashes. Once it finds the ordinal that refers to the function, it uses this index to get the address of the function using AddressOfFunctions list.
Figure 7. Resolving function address using the ordinal as an index to AddressOfFunctions list
The hashing function being used to identify the library and function names is custom and uses a parameter that makes it support both ASCII and UNICODE names. It will first use UNICODE hashing when parsing InLoadOrderModuleList (as it loads UNICODE_STRINGDllBase) and ASCII when accessing the AddressOfNames list from the Export Directory.
Figure 8. Custom hashing function from Layer 2 supporting both ASCII and UNICODE encodings
Once the malware has resolved LoadLibraryA and GetProcAddress from kernel32.dll, it will then use these functions to resolve more necessary APIs and save them in a “Function Table”. To resolve them, it relies on loading strings in the stack before the call to GetProcAddress. The API calls being resolved are:
GlobalAlloc
GetLastError
Sleep
VirtualAlloc
CreateToolhelp32Snapshot
Module32First
CloseHandle
Figure 9. Layer 2 resolving functions dynamically for later use
Decryption of Layer 3 After resolving .dlls and the functions it enters in the following procedure, responsible of preparing the next stage, allocating space for it and transferring its execution through a JMP instruction.
Figure 10. Decryption and execution of Layer 3 (final layer)
Layer 3 This is the last layer before having the unpacked Taurus Stealer. This last phase is very similar to the previous one but surprisingly less stealthy (the use of hashes to find .dlls and API calls has been removed) now strings stored in the stack, and string comparisons, are used instead. However, some previously unseen new features have been added to this stage, such as anti-emulation checks. This is how it looks the beginning of this last layer. The value at the address 0x00200038 is now empty but will be overwritten later with the OEP (Original Entry Point). When calling unpack the first instruction will execute POP EAX to get the address of the OEP, check whether it is already set and jump accordingly. If not, it will start the final unpacking process and then a JMP EAX will transfer execution to the final Taurus Stealer.
Figure 11. OEP is set. Last Layer before and after the unpacking process.
Finding DLLs and Functions As in the 2nd layer, it will parse the PEB to find DllBase of kernel32.dll walking through InLoadOrderModuleList, and then parse kernel32.dll Exports Directory to find the address of LoadLibraryA and GetProcAddress. This process is very similar to the one seen in the previous layer, but names are stored in the stack instead of using a custom hash function.
Figure 12. Last layer finding APIs by name stored in the stack instead of using the hashing approach
Once it has access to LoadLibraryA and GetProcAddressA it will start resolving needed API calls. It will do so by storing strings in the stack and storing the function addresses in memory. The functions being resolved are:
VirtualAlloc
VirtualProtect
VirtualFree
GetVersionExA
TerminateProcess
ExitProcess
SetErrorMode
Figure 13. Last Layer dynamically resolving APIs before the final unpack
Anti-Emulation After resolving these API calls, it enters in a function that will prevent the malware from detonating if it is being executed in an emulated environment. We‘ve named this function anti_emulation. It uses a common environment-based opaque predicate calling SetErrorMode API call.
Figure 14. Anti-Emulation technique used before transferring execution to the final Taurus Stealer
This technique has been previously documented. The code calls SetErrorMode() with a known value (1024) and then calls it again with a different one. SetErrorMode returns the previous state of the error-mode bit flags. An emulator not implementing this functionality properly (saving the previous state), would not behave as expected and would finish execution at this point. Transfer execution to Taurus Stealer After this, the packer will allocate memory to copy the clean Taurus Stealer process in, parse its PE (more precisely its Import Table) and load all the necessary imported functions. As previously stated, during this process the offset 0x00200038 from earlier will be overwritten with the OEP (Original Entry Point). Finally, execution gets transferred to the unpacked Taurus Stealer via JMP EAX.
Figure 15. Layer 3 transferring execution to the final unpacked Taurus Stealer
We can dump the unpacked Taurus Stealer from memory (for example after copying the clean Taurus process, before the call to VirtualFree). We will focus the analysis on the unpacked sample with hash d6987aa833d85ccf8da6527374c040c02e8dfbdd8e4e4f3a66635e81b1c265c8.
Taurus Stealer (Unpacked)
The following figure shows Taurus Stealer’s main workflow. Its life cycle is not very different from other malware stealers. However, it is worth mentioning that the Anti-CIS feature (avoid infecting machines coming from the Commonwealth of Independent States) is not optional and is the first feature being executed in the malware.
Figure 16. Taurus Stealer main workflow
After loading its initial configuration (which includes resolving APIs, Command and Control server, Build Id, etc.), it will go through two checks that prevent the malware from detonating if it is running in a machine coming from the Commonwealth of Independent States (CIS) and if it has a modified C2 (probably to avoid detonating on cracked builds). These two initial checks are mandatory. After passing the initial checks, it will establish communication with its C2 and retrieve dynamic configuration (or a static default one if the C2 is not available) and execute the functionalities accordingly before exfiltration. After exfiltration, two functionalities are left: Loader and Self-Delete (both optional). Following this, a clean-up routine will be responsible for deleting strings from memory before finishing execution. Code Obfuscation Taurus Stealer makes heavy use of code obfuscation techniques throughout its execution, which translates to a lot of code for every little task the malware might perform. Taurus string obfuscation is done in an attempt to hide traces and functionality from static tools and to slow down analysis. Although these techniques are not complex, there is almost no single relevant string in cleartext. We will mostly find:
XOR encrypted strings
SUB encrypted strings
XOR encrypted strings We can find encrypted strings being loaded in the stack and decrypted just before its use. Taurus usually sets an initial hardcoded XOR key to start decrypting the string and then decrypts it in a loop. There are different variations of this routine. Sometimes there is only one hardcoded key, whilst other times there is one initial key that decrypts the first byte of the string, which is used as the rest of the XOR key, etc. The following figure shows the decryption of the string “\Monero” (used in the stealing process). We can see that the initial key is set with ‘PUSH + POP’ and then the same key is used to decrypt the whole string byte per byte. Other approaches use strcpy to load the initial encrypted string directly, for instance.
Figure 17. Example of “\Monero” XOR encrypted string
SUB encrypted strings This is the same approach as with XOR encrypted strings, except for the fact that the decryption is done with subtraction operations. There are different variations of this technique, but all follow the same idea. In the following example, the SUB key is found at the beginning of the encrypted string and decryption starts after the first byte.
Figure 18. Example of “DisplayVersion” SUB encrypted string
Earlier Taurus versions made use of stack strings to hide strings (which can make code blocks look very long). However, this method has been completely removed by the XOR and SUB encryption schemes – probably because these methods do not show the clear strings unless decryption is performed or analysis is done dynamically. Comparatively, in stack strings, one can see the clear string byte per byte. Here is an example of such a replacement from an earlier Taurus sample, when resolving the string “wallet.dat” for DashCore wallet retrieval purposes. This is now done via XOR encryption:
Figure 19. Stack strings are replaced by XOR and SUB encrypted strings
The combination of these obfuscation techniques leads to a lot of unnecessary loops that slow down analysis and hide functionality from static tools. As a result, the graph view of the core malware looks like this:
Resolving APIs The malware will resolve its API calls dynamically using hashes. It will first resolve LoadLibraryA and GetProcAddress from kernel32.dll to ease the resolution of further API calls. It does so by accessing the PEB of the process – more precisely to access the DllBase property of the third element from the InLoadOrderModuleList (which happens to be “kernel32.dll”) – and then use this address to walk through the Export Directory information.
Figure 21. Retrieving kernel32.dll DllBase by accessing the 3rd entry in the InLoadOrderModuleList list
It will iterate kernel32.dllAddressOfNames structure and compute a hash for every exported function until the corresponding hash for “LoadLibraryA” is found. The same process is repeated for the “GetProcAddress” API call. Once both procedures are resolved, they are saved for future resolution of API calls.
Figure 22. Taurus Stealer iterates AddressOfNames to find an API using a hashing approach
For further API resolutions, a “DLL Table String” is used to index the library needed to load an exported function and then the hash of the needed API call.
Figure 23. DLL Table String used in API resolutions
Resolving initial Configuration Just as with Predator The Thief, Taurus Stealer will load its initial configuration in a table of function pointers before the execution of the WinMain() function. These functions are executed in order and are responsible for loading the C2, Build Id and the Bot Id/UUID. C2 and Build Id are resolved using the SUB encryption scheme with a one-byte key. The loop uses a hard-coded length, (the size in bytes of the C2 and Build Id), which means that this has been pre-processed beforehand (probably by the builder) and that these procedures would work for only these properties.
Figure 24. Taurus Stealer decrypting its Command and Control server
BOT ID / UUID Generation Taurus generates a unique identifier for every infected machine. Earlier versions of this malware also used this identifier as the .zip filename containing the stolen data. This behavior has been modified and now the .zip filename is randomly generated (16 random ASCII characters).
Figure 25. Call graph from the Bot Id / UUID generation routine
It starts by getting a bitmask of all the currently available disk drives using GetLogicalDrivers and retrieving their VolumeSerialNumber with GetVolumeInformationA. All these values are added into the register ESI (holds the sum of all VolumeSerialNumbers from all available Drive Letters). ESI is then added to itself and right-shifted 3 bytes. The result is a hexadecimal value that is converted to decimal. After all this process, it takes out the first two digits from the result and concatenates its full original part at the beginning. The last step consists of transforming digits in odd positions to ASCII letters (by adding 0x40). As an example, let’s imagine an infected machine with “C:\\”, “D:\\” and “Z:\\” drive letters available.
1. Call GetLogicalDrivers to get a bitmask of all the currently available disk drives.
2. Get their VolumeSerialNumber using GetVolumeInformationA: ESI holds the sum of all VolumeSerialNumber from all available Drive Letters GetVolumeInformationA(“C:\\”) -> 7CCD8A24h GetVolumeInformationA(“D:\\”) -> 25EBDC39h GetVolumeInformationA(“Z:\\”) -> 0FE01h ESI = sum(0x7CCD8A24+0x25EBDC3+0x0FE01) = 0xA2BA645E
3. Once finished the sum, it will: mov edx, esi edx = (edx >> 3) + edx Which translates to: (0xa2ba645e >> 0x3) + 0xa2ba645e = 0xb711b0e9
4. HEX convert the result to decimal result = hex(0xb711b0e9) = 3071389929
5. Take out the first two digits and concatenate its full original part at the beginning: 307138992971389929
6. Finally, it transforms digits in odd positions to ASCII letters: s0w1s8y9r9w1s8y9r9
Anti – CIS
Taurus Stealer tries to avoid infection in countries belonging to the Commonwealth of Independent States (CIS) by checking the language identifier of the infected machine via GetUserDefaultLangID. Earlier Taurus Stealer versions used to have this functionality in a separate function, whereas the latest samples include this in the main procedure of the malware. It is worth mentioning that this feature is mandatory and will be executed at the beginning of the malware execution.
Figure 26. Taurus Stealer Anti-CIS feature
GetUserDefaultLandID returns the language identifier of the Region Format setting for the current user. If it matches one on the list, it will finish execution immediately without causing any harm.
Language Id
SubLanguage Symbol
Country
0x419
SUBLANG_RUSSIAN_RUSSIA
Russia
0x42B
SUBLANG_ARMENIAN_ARMENIA
Armenia
0x423
SUBLANG_BELARUSIAN_BELARUS
Belarus
0x437
SUBLANG_GEORGIAN_GEORGIA
Georgia
0x43F
SUBLANG_KAZAK_KAZAKHSTAN
Kazakhstan
0x428
SUBLANG_TAJIK_TAJIKISTAN
Tajikistan
0x843
SUBLANG_UZBEK_CYRILLIC
Uzbekistan
0x422
SUBLANG_UKRAINIAN_UKRAINE
Ukraine
Table 2. Taurus Stealer Language Id whitelist (Anti-CIS)
Anti – C2 Mod. After the Anti-CIS feature has taken place, and before any harmful activity occurs, the retrieved C2 is checked against a hashing function to avoid running with an invalid or modified Command and Control server. This hashing function is the same used to resolve API calls and is as follows:
Figure 27. Taurus Stealer hashing function
Earlier taurus versions make use of the same hashing algorithm, except they execute two loops instead of one. If the hash of the C2 is not matching the expected one, it will avoid performing any malicious activity. This is most probably done to protect the binary from cracked versions and to avoid leaving traces or uncovering activity if the sample has been modified for analysis purposes.
C2 Communication
Perhaps the biggest change in this new Taurus Stealer version is how the communications with the Command and Control Server are managed. Earlier versions used two main resources to make requests:
Resource
Description
/gate/cfg/?post=1&data=<bot_id>
Register Bot Id and get dynamic config. Everything is sent in cleartext
/gate/log?post=2&data=<summary_information>
Exfiltrate data in ZIP (cleartext) summary_information is encrypted
Table 3. Networking resources from earlier Taurus versions
his new Taurus Stealer version uses:
Resource
Description
/cfg/
Register Bot Id and get dynamic config. BotId is sent encrypted
/dlls/
Ask for necessary .dlls (Browsers Grabbing)
/log/
Exfiltrate data in ZIP (encrypted)
/loader/complete/
ACK execution of Loader module
Table 4. Networking resources from new Taurus samples
This time no data is sent in cleartext. Taurus Stealer uses wininet APIs InternetOpenA, InternetSetOptionA, InternetConnectA, HttpOpenRequestA, HttpSendRequestA, InternetReadFile and InternetCloseHandle for its networking functionalities.
The way Taurus generates the User-Agent that it will use for networking purposes is different from earlier versions and has introduced more steps in its creation, ending up in more variable results. This routine follows the next steps:
1. It will first get OS Major Version and OS Minor Version information from the PEB. In this example, we will let OS Major Version be 6 and OS Minor Version be 1.
1.1 Read TIB[0x30] -> PEB[0x0A] -> OS Major Version -> 6
1.2 Read PEB[0xA4] -> OS Minor Version -> 1
2. Call to IsWow64Process to know if the process is running under WOW64 (this will be needed later).
3. Decrypt string “.121 Safari/537.36”
4. Call GetTickCount and store result in EAX (for this example: EAX = 0x0540790F)
8. Check the result from the previous call to IsWow64Process and store it for later.
8.1 If the process is running under WOW64: Decrypt the string “ WOW64)”
8.2 If the process is not running under WOW64: Load char “)” In this example we will assume the process is running under WOW64.
9. Transform from HEX to decimal OS Minor Version (“1”)
10. Transform from HEX to decimal OS Major Version (“6”)
11. Decrypt string “Mozilla/5.0 (Windows NT ”
12. Append OS Major Version -> “Mozilla/5.0 (Windows NT 6”
13. Append ‘.’ (hardcoded) -> “Mozilla/5.0 (Windows NT 6.”
14. Append OS Minor Version -> “Mozilla/5.0 (Windows NT 6.1”
15. Append ‘;’ (hardcoded) -> “Mozilla/5.0 (Windows NT 6.1;”
16. Append the WOW64 modifier explained before -> “Mozilla/5.0 (Windows NT 6.1; WOW64)”
17. Append string “ AppleWebKit / 537.36 (KHTML, like Gecko) Chrome / 83.0.” -> “Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit / 537.36 (KHTML, like Gecko) Chrome / 83.0.”
18. Append result of from the earlier GetTickCount (1375 after its processing) -> “Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit / 537.36 (KHTML, like Gecko) Chrome / 83.0.1375”
19. Append the string “.121 Safari/537.36” to get the final result:
“Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit / 537.36 (KHTML, like Gecko) Chrome / 83.0.1375.121 Safari/537.36”
Which would have looked like this if the process was not running under WOW64:
“Mozilla/5.0 (Windows NT 6.1;) AppleWebKit / 537.36 (KHTML, like Gecko) Chrome / 83.0.1375.121 Safari/537.36”
The bold characters from the generated User-Agent are the ones that could vary depending on the OS versions, if the machine is running under WOW64 and the result of GetTickCount call.
How the port is set In the analyzed sample, the port for communications is set as a hardcoded value in a variable that is used in the code. This setting is usually hidden. Sometimes a simple “push 80” in the middle of the code, or a setting to a variable using “mov [addr], 0x50” is used. Other samples use https and set the port with a XOR operation like “0x3a3 ^ 0x218” which evaluates to “443”, the standard https port. In the analyzed sample, before any communication with the C2 is made, a hardcoded “push 0x50 + pop EDI” is executed to store the port used for communications (port 80) in EDI. EDI register will be used later in the code to access the communications port where necessary. The following figure shows how Taurus Stealer checks which is the port used for communications and how it sets dwFlags for the call to HttpOpenRequestA accordingly.
Figure 29. Taurus Stealer sets dwFlags according to the port
So, if the samples uses port 80 or any other port different from 443, the following flags will be used:
RC4 Taurus Stealer uses RC4 stream cipher as its first layer of encryption for communications with the C2. The symmetric key used for this algorithm is randomly generated, which means the key will have to be stored somewhere in the body of the message being sent so that the receiver can decrypt the content. Key Generation The procedure we’ve named getRandomString is the routine called by Taurus Stealer to generate the RC4 symmetric key. It receives 2 parameters, the first is an output buffer that will receive the key and the second is the length of the key to be generated. To create the random chunk of data, it generates an array of bytes loading three XMM registers in memory and then calling rand() to get a random index that it will use to get a byte from this array. This process is repeated for as many bytes as specified by the second parameter. Given that all the bytes in these XMM registers are printable, this suggests that getRandomString produces an alphanumeric key of n bytes length.
Figure 30. Taurus Stealer getRandomString routine
Given the lack of srand, no seed is initialized and the rand function will end up giving the same “random” indexes. In the analyzed sample, there is only one point in which this functionality is called with a different initial value (when creating a random directory in %PROGRAMDATA% to store .dlls, as we will see later). We’ve named this function getRandomString2 as it has the same purpose. However, it receives an input buffer that has been processed beforehand in another function (we’ve named this function getRandomBytes). This input buffer is generated by initializing a big buffer and XORing it over a loop with the result of a GetTickCount call. This ends up giving a “random” input buffer which getRandomString2 will use to get indexes to an encrypted string that resolves in runtime as “ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789”, and finally generate a random string for a given length. We have seen other Taurus Stealer samples moving onto this last functionality (using input buffers XORed with the result of a GetTickCount call to generate random chunks of data) every time randomness is needed (generation communication keys, filenames, etc.). The malware sample d0aa932e9555a8f5d9a03a507d32ab3ef0b6873c4d9b0b34b2ac1bd68f1abc23 is an example of these Taurus Stealer variants.
Figure 31. Taurus Stealer getRandomBytes routine
BASE64 This is the last encoding layer before C2 communications happen. It uses a classic BASE64 to encode the message (that has been previously encrypted with RC4) and then, after encoding, the RC4 symmetric key is appended to the beginning of the message. The receiver will then need to get the key from the beginning of the message, BASE64 decode the rest of it and use the retrieved key to decrypt the final RC4 encrypted message. To avoid having a clear BASE64 alphabet in the code, it uses XMM registers to load an encrypted alphabet that is decrypted using the previously seen SUB encryption scheme before encoding.
Figure 32. Taurus Stealer hiding Base64 alphabet
This is what the encryption procedure would look like:
1. Generate RC4 key using getRandomString with a hardcoded size of 16 bytes.
2. RC4 encrypt the message using the generated 16 byte key.
3. BASE64encode the encrypted message.
4. Append RC4 symmetric key at the beginning of the encoded message.
Figure 33. Taurus Stealer encryption routine
Bot Registration + Getting dynamic configuration Once all the initial checks have been successfully passed, it is time for Taurus to register this new Bot and retrieve the dynamic configuration. To do so, a request to the resource /cfg/ of the C2 is made with the encrypted Bot Id as a message. For example, given a BotId “s0w1s8y9r9w1s8y9r9 and a key “IDaJhCHdIlfHcldJ”:
The responses go through a decryption routine that will reverse the steps described above to get the plaintext message. As you can see in the following figure, the key length is hardcoded in the binary and expected to be 16 bytes long.
Figure 34. Taurus Stealer decrypting C2 responses
To decrypt it, we do as follow: 1. Get RC4 key (first 16 bytes of the message) xBtSRalRvNNFBNqA 2. BASE64 decode the rest of the message (after the RC4 key)
3. Decrypt the message using RC4 key (get dynamic config.) [1;1;1;1;1;0;1;1;1;1;1;1;1;1;1;1;1;5000;0;0]#[]#[156.146.57.112;US]#[] We can easily see that consecutive configurations are separated by the character “;”, while the character ‘#’ is used to separate different configurations. We can summarize them like this: [STEALER_CONFIG]#[GRABBER_CONFIG]#[NETWORK_CONFIG]#[LOADER_CONFIG] In case the C2 is down and no dynamic configuration is available, it will use a hardcoded configuration stored in the binary which would enable all stealers, Anti-VM, and Self-Delete features. (Dynamic Grabber and Loader modules are not enabled by default in the analyzed sample).
Figure 35. Taurus uses a static hardcoded configuration If C2 is not available
Anti – VM (optional) This functionality is optional and depends on the retrieved configuration. If the malware detects that it is running in a Virtualized environment, it will abort execution before causing any damage. It makes use of old and common x86 Anti-VM instructions (like the RedPill technique) to detect the Virtualized environment in this order:
SIDT
SGDT
STR
CPUID
SMSW
Figure 36. Taurus Stealer Anti-VM routine
Stealer / Grabber
We can distinguish 5 main grabbing methods used in the malware. All paths and strings required, as usual with Taurus Stealer, are created at runtime and come encrypted in the methods described before. Grabber 1 This is one of the most used grabbing methods, along with the malware execution (if it is not used as a call to the grabbing routine it is implemented inside another function in the same way), and consists of traversing files (it ignores directories) by using kernel32.dllFindFirstFileA, FindNextFileA and FindClose API calls. This grabbing method does not use recursion. The grabber expects to receive a directory as a parameter for those calls (it can contain wildcards) to start the search with. Every found file is grabbed and added to a ZIP file in memory for future exfiltration. An example of its use can be seen in the Wallets Stealing functionality, when searching, for instance, for Electrum wallets: Grabber 2 This grabber is used in the Outlook Stealing functionality and uses advapi32.dllRegOpenKeyA, RegEnumKeyA, RegQueryValueExA and RegCloseKey API calls to access the and steal from Windows Registry. It uses a recursive approach and will start traversing the Windows Registry searching for a specific key from a given starting point until RegEnumKeyA has no more keys to enumerate. For instance, in the Outlook Stealing functionality this grabber is used with the starting Registry key “HKCU\software\microsoft\office” searching for the key “9375CFF0413111d3B88A00104B2A667“. Grabber 3 This grabber is used to steal browsers data and uses the same API calls as Grabber 1 for traversing files. However, it loops through all files and directories from %USERS% directory and favors recursion. Files found are processed and added to the ZIP file in memory. One curious detail is that if a “wallet.dat” is found during the parsing of files, it will only be dumped if the current depth of the recursion is less or equal to 5. This is probably done in an attempt to avoid dumping invalid wallets. We can summarize the files Taurus Stealer is interested in the following table:
Grabbed File
Affected Software
History
Browsers
formhistory.sqlite
Mozilla Firefox & Others
cookies.sqlite
Mozilla Firefox & Others
wallet.dat
Bitcoin
logins.json
Chrome
signongs.sqlite
Mozilla Firefox & Others
places.sqlite
Mozilla Firefox & Others
Login Data
Chrome / Chromium based
Cookies
Chrome / Chromium based
Web Data
Browser
Table 5. Taurus Stealer list of files for Browser Stealing functionalities
Grabber 4
This grabber steals information from the Windows Vault, which is the default storage vault for the credential manager information. This is done through the use of Vaultcli.dll, which encapsulates the necessary functions to access the Vault. Internet Explorer data, since it’s version 10, is stored in the Vault. The malware loops through its items using:
VaultEnumerateVaults
VaultOpenVault
VaultEnumerateItems
VaultGetItem
VaultFree
Grabber 5 This last grabber is the customized grabber module (dynamic grabber). This module is responsible for grabbing files configured by the threat actor operating the botnet. When Taurus makes its first request to the C&C, it retrieves the malware configuration, which can include a customized grabbing configuration to search and steal files. This functionality is not enabled in the default static configuration from the analyzed sample (the configuration used when the C2 is not available). As in earlier grabbing methods, this is done via file traversing using kernel32.dll FindFirstFileA, FindNextFileA and FindClose API calls. The threat actor may set recursive searches (optional) and multiple wildcards for the search.
Figure 37. Threat Actor can add customized grabber rules for the dynamic grabber
Targeted Software This is the software the analyzed sample is targeting. It has functionalities to steal from: Wallets:
Electrum
MultiBit
Armory
Ethereum
Bytecoin
Jaxx
Atomic
Exodus
Dahscore
Bitcoin
Wasabi
Daedalus
Monero
Games:
Steam
Communications:
Telegram
Discord
Jabber
Mail:
FoxMail
Outlook
FTP:
FileZilla
WinSCP
2FA Software:
Authy
VPN:
NordVPN
Browsers:
Mozilla Firefox (also Gecko browsers)
Chrome (also Chromium browsers)
Internet Explorer
Edge
Browsers using the same files the grabber targets.
However, it has been seen in other samples and their advertisements that Taurus Stealer also supports other software not included in the list like BattleNet, Skype and WinFTP. As mentioned earlier, they also have an open communication channel with their customers, who can suggest new software to add support to. Stealer Dependencies Although the posts that sell the malware in underground forums claim that Taurus Stealer does not have any dependencies, when stealing browser information (by looping through files recursively using the “Grabber 3” method described before), if it finds “logins.json” or “signons.sqlite” it will then ask for needed .dlls to its C2. It first creates a directory in %PROGRAMDATA%\<bot id>, where it is going to dump the downloaded .dlls. It will check if “%PROGRAMDATA%\<bot id>\nss3.dll” exists and will ask for its C2 (doing a request to /dlls/ resource) if not. The .dlls will be finally dumped in the following order:
1. freebl3.dll
2. mozglue.dll
3. msvcp140.dll
4. nss3.dll
5. softokn3.dll
6. vcruntime140.dll
If we find the C2 down (when analyzing the sample, for example), we will not be able to download the required files. However, the malware will still try, no matter what, to load those libraries after the request to /dlls/ has been made (starting by loading “nss3.dll”), which would lead to a crash. The malware would stop working from this point. In contrast, if the C2 is alive, the .dlls will be downloaded and written to disk in the order mentioned before. The following figure shows the call graph from the routine responsible for requesting and dumping the required libraries to disk.
Figure 38. Taurus Stealer dumping retrieved .dlls from its Command and Control Server to disk
Information Gathering After the Browser stealing process is finished, Taurus proceeds to gather information from the infected machine along with the Taurus Banner and adds this data to the ZIP file in memory with the filename “Information.txt”. All this functionality is done through a series of unnecessary steps caused by all the obfuscation techniques to hide strings, which leads to a horrible function call graph:
Figure 39. Taurus Stealer main Information Gathering routine call graph
It gets information and concatenates it sequentially in memory until we get the final result:
One curious difference from earlier Taurus Stealer versions is that the Active Window from the infected machine is now also included in the information gathering process.
Enumerate Installed Software As part of the information gathering process, it will try to get a list of the installed software from the infected machine by looping in the registry from “HKLM\SOFTWARE\Microsoft\Windows\CurrentVersion\Uninstall” and retrieving DisplayName and DisplayVersion with RegQueryValueExA until RegEnumKeyA does not find more keys. If software in the registry list has the key “DisplayName”, it gets added to the list of installed software. Then, if it also has “Display Version” key, the value is appended to the name. In case this last key is not available, “[Unknown]” is appended instead. Following the pattern: “DisplayName\tDisplayVersion” As an example:
The list of software is included in the ZIP file in memory with the filename “Installed Software.txt”
C2 Exfiltration
During the stealing process, the data that is grabbed from the infected machine is saved in a ZIP file in memory. As we have just seen, information gathering files are also included in this fileless ZIP. When all this data is ready, Taurus Stealer will proceed to:
1. Generate a Bot Id results summary message.
2. Encrypt the ZIP file before exfiltration.
3. Exfiltrate the ZIP file to Command and Control server.
4. Delete traces from networking activity
Generate Bot Id results summary The results summary message is created in 2 stages. The first stage loads generic information from the infected machine (Bot Id, Build Id, Windows version and architecture, current user, etc.) and a summary count of the number of passwords, cookies, etc. stolen. As an example:
Finally, it concatenates a string that represents a mask stating which Software has been available to steal information from (e.g. Telegram, Discord, FileZilla, WinSCP. etc.).
This summary information is then added in the memory ZIP file with the filename “LogInfo.txt”. This behavior is different from earlier Taurus Stealer versions, where the information was sent as part of the URL (when doing exfiltration POST request to the resource /gate/log/) in the parameter “data”. Although this summary information was encrypted, the exfiltrated ZIP file was sent in cleartext. Encrypt ZIP before exfiltration Taurus Stealer will then encrypt the ZIP file in memory using the techniques described before: using the RC4 stream cipher with a randomly generated key and encoding the result in BASE64. Because the RC4 key is needed to decrypt the message, the key is included at the beginning of the encoded message. In the analyzed sample, as we saw before, the key length is hardcoded and is 16 bytes. As an example, this could be an encrypted message being sent in a POST request to the /log/ resource of a Taurus Stealer C2, where the RC4 key is included at the beginning of the message (first 16 characters).
Exfiltrate ZIP file to Command and Control server As in the earlier versions, it uses a try-retry logic where it will try to exfiltrate up to 10 times (in case the network is failing, C2 is down, etc.). It does so by opening a handle using HttpOpenRequestA for the “/log/” resource and using this handle in a call to HttpSendRequestA, where exfiltration is done (the data to be exfiltrated is in the post_data argument). The following figure shows this try-retry logic in a loop that executes HttpSendRequestA.
Figure 40. Taurus Stealer will try to exfiltrate up to 10 times
The encrypted ZIP file is sent with Content-Type: application/octet-stream. The filename is a randomly generated string of 16 bytes. However, earlier Taurus Stealer versions used the Bot Id as the .zip filename. Delete traces from networking activity After exfiltration, it uses DeleteUrlCacheEntry with the C2 as a parameter for the API call, which deletes the cache entry for a given URL. This is the last step of the exfiltration process and is done to avoid leaving traces from the networking activity in the infected machine.
Loader (optional)
Upon exfiltration, the Loader module is executed. This module is optional and gets its configuration from the first C2 request. If the module is enabled, it will load an URL from the Loader configuration and execute URLOpenBlockingStream to download a file. This file will then be dumped in %TEMP% folder using a random filename of 8 characters. Once the file has been successfully dumped in the infected machine it will execute it using ShellExecuteA with the option nShowCmd as “SW_HIDE”, which hides the window and activates another one. If persistence is set in the Loader configuration, it will also schedule a task in the infected machine to run the downloaded file every minute using:
The next figure shows the Schedule Task Manager from an infected machine where the task has been scheduled to run every minute indefinitely.
Figure 41. Loader persistence is carried out by creating a scheduled task to run every minute indefinitely
Once the file is executed, a new POST request is made to the C2 to the resource /loader/complete/. The following figure summarizes the main responsibilities of the Loader routine.
This functionality is the last one being executed in the malware and is also optional, although it is enabled by default if no response from the C2 was received in the first request. It will use CreateProcessA to execute cmd.exe with the following arguments:
cmd.exe /c timeout /t 3 & del /f /q <malware_filepath>
Malware_filepath is the actual path of the binary being executed (itself). A small timeout is set to give time to the malware to finish its final tasks. After the creation of this process, only a clean-up routine is executed to delete strings from memory before finishing execution.
YARA rule
This memory Yara rule detects both old and new Taurus Stealer versions. It targets some unique functionalities from this malware family:
Hex2Dec: Routine used to convert from a Hexadecimal value to a Decimal value.
Bot Id/UUID generation routine.
getRandomString: Routine used to generate a random string using rand() over a static input buffer
getRandomString2: Routine used to generate a random string using rand() over an input buffer previously “randomized” with GetTickCount
getRandomBytes: Routine to generate “random” input buffers for getRandomString2
Hashing algorithm used to resolve APIs and Anti – C2 mod. feature.
Information Stealers like Taurus Stealer are dangerous and can cause a lot of damage to individuals and organizations (privacy violation, leakage of confidential information, etc.). Consequences vary depending on the significance of the stolen data. This goes from usernames and passwords (which could be targetted by threat actors to achieve privilege escalation and lateral movement, for example) to information that grants them immediate financial profit, such as cryptocurrency wallets. In addition, stolen email accounts can be used to send spam and/or distribute malware. As has been seen throughout the analysis, Taurus Stealer looks like an evolving malware that is still being updated (improving its code by adding features, more obfuscation and bugfixes) as well as it’s Panel, which keeps having updates with more improvements (such as adding filters for the results coming from the malware or adding statistics for the loader). The fact the malware is being actively used in the wild suggests that it will continue evolving and adding more features and protections in the future, especially as customers have an open dialog channel to request new software to target or to suggest improvements to improve functionality. For more details about how we reverse engineer and analyze malware, visit our targeted malware module page.
Whenever I reverse a sample, I am mostly interested in how it was developed, even if in the end the techniques employed are generally the same, I am always curious about what was the way to achieve a task, or just simply understand the code philosophy of a piece of code. It is a very nice way to spot different trending and discovering (sometimes) new tricks that you never know it was possible to do. This is one of the main reasons, I love digging mostly into stealers/clippers for their accessibility for being reversed, and enjoying malware analysis as a kind of game (unless some exceptions like Nymaim that is literally hell).
It’s been 1 year and a half now that I start looking into “Predator The Thief”, and this malware has evolved over time in terms of content added and code structure. This impression could be totally different from others in terms of stealing tasks performed, but based on my first in-depth analysis,, the code has changed too much and it was necessary to make another post on it.
This one will focus on some major aspects of the 3.3.2 version, but will not explain everything (because some details have already been mentioned in other papers, some subjects are known). Also, times to times I will add some extra commentary about malware analysis in general.
Anti-Disassembly
When you open an unpacked binary in IDA or other disassembler software like GHIDRA, there is an amount of code that is not interpreted correctly which leads to rubbish code, the incapacity to construct instructions or showing some graph. Behind this, it’s obvious that an anti-disassembly trick is used.
The technique exploited here is known and used in the wild by other malware, it requires just a few opcodes to process and leads at the end at the creation of a false branch. In this case, it begins with a simple xor instruction that focuses on configuring the zero flag and forcing the JZ jump condition to work no matter what, so, at this stage, it’s understandable that something suspicious is in progress. Then the MOV opcode (0xB8) next to the jump is a 5 bytes instruction and disturbing the disassembler to consider that this instruction is the right one to interpret beside that the correct opcode is inside this one, and in the end, by choosing this wrong path malicious tasks are hidden.
Of course, fixing this issue is simple, and required just a few seconds. For example with IDA, you need to undefine the MOV instruction by pressing the keyboard shortcut “U”, to produce this pattern.
Then skip the 0xB8 opcode, and pushing on “C” at the 0xE8 position, to configure the disassembler to interpret instruction at this point.
Replacing the 0xB8 opcode by 0x90. with a hexadecimal editor, will fix the issue. Opening again the patched PE, you will see that IDA is now able to even show the graph mode.
After patching it, there are still some parts that can’t be correctly parsed by the disassembler, but after reading some of the code locations, some of them are correct, so if you want to create a function, you can select the “loc” section then pushed on “P” to create a sub-function, of course, this action could lead to some irreversible thing if you are not sure about your actions and end to restart again the whole process to remove a the ant-disassembly tricks, so this action must be done only at last resort.
Code Obfuscation
Whenever you are analyzing Predator, you know that you will have to deal with some obfuscation tricks almost everywhere just for slowing down your code analysis. Of course, they are not complicated to assimilate, but as always, simple tricks used at their finest could turn a simple fun afternoon to literally “welcome to Dark Souls”. The concept was already there in the first in-depth analysis of this malware, and the idea remains over and over with further updates on it. The only differences are easy to guess :
More layers of obfuscation have been added
Techniques already used are just adjusted.
More dose of randomness
As a reversing point of view, I am considering this part as one the main thing to recognized this stealer, even if of course, you can add network communication and C&C pattern as other ways for identifying it, inspecting the code is one way to clarify doubts (and I understand that this statement is for sure not working for every malware), but the idea is that nowadays it’s incredibly easy to make mistakes by being dupe by rules or tags on sandboxes, due to similarities based on code-sharing, or just literally creating false flag.
GetModuleAddress
Already there in a previous analysis, recreating the GetProcAddress is a popular trick to hide an API call behind a simple register call. Over the updates, the main idea is still there but the main procedures have been modified, reworked or slightly optimized.
First of all, we recognized easily the PEB retrieved by spotting fs[0x30] behind some extra instructions.
then from it, the loader data section is requested for two things:
Getting the InLoadOrderModuleList pointer
Getting the InMemoryOrderModuleList pointer
For those who are unfamiliar by this, basically, the PEB_LDR_DATA is a structure is where is stored all the information related to the loaded modules of the process.
Then, a loop is performing a basic search on every entry of the module list but in “memory order” on the loader data, by retrieving the module name, generating a hash of it and when it’s done, it is compared with a hardcoded obfuscated hash of the kernel32 module and obviously, if it matches, the module base address is saved, if it’s not, the process is repeated again and again.
The XOR kernel32 hashes compared with the one created
Nowadays, using hashes for a function name or module name is something that you can see in many other malware, purposes are multiple and this is one of the ways to hide some actions. An example of this code behavior could be found easily on the internet and as I said above, this one is popular and already used.
GetProcAddress / GetLoadLibrary
Always followed by GetModuleAddress, the code for recreating GetProcAddress is by far the same architecture model than the v2, in term of the concept used. If the function is forwarded, it will basically perform a recursive call of itself by getting the forward address, checking if the library is loaded then call GetProcAddress again with new values.
Xor everything
It’s almost unnecessary to talk about it, but as in-depth analysis, if you have never read the other article before, it’s always worth to say some words on the subject (as a reminder). The XOR encryption is a common cipher that required a rudimentary implementation for being effective :
Only one operator is used (XOR)
it’s not consuming resources.
It could be used as a component of other ciphers
This one is extremely popular in malware and the goal is not really to produce strong encryption because it’s ridiculously easy to break most of the time, they are used for hiding information or keywords that could be triggering alerts, rules…
Communication between host & server
Hiding strings
Or… simply used as an absurd step for obfuscating the code
etc…
A typical example in Predator could be seeing huge blocks with only two instructions (XOR & MOV), where stacks strings are decrypted X bytes per X bytes by just moving content on a temporary value (stored on EAX), XORed then pushed back to EBP, and the principle is reproduced endlessly again and again. This is rudimentary, In this scenario, it’s just part of the obfuscation process heavily abused by predator, for having an absurd amount of instruction for simple things.
Also for some cases, When a hexadecimal/integer value is required for an API call, it could be possible to spot another pattern of a hardcoded string moved to a register then only one XOR instruction is performed for revealing the correct value, this trivial thing is used for some specific cases like the correct position in the TEB for retrieving the PEB, an RVA of a specific module, …
Finally, the most common one, there is also the classic one used by using a for loop for a one key length XOR key, seen for decrypting modules, functions, and other things…
str = ... # encrypted string
for i, s in enumerate(str):
s[i] = s[i] ^ s[len(str)-1]
Sub everything
Let’s consider this as a perfect example of “let’s do the same exact thing by just changing one single instruction”, so in the end, a new encryption method is used with no effort for the development. That’s how a SUB instruction is used for doing the substitution cipher. The only difference that I could notice it’s how the key is retrieved.
Besides having something hardcoded directly, a signed 32-bit division is performed, easily noticeable by the use of cdq & idiv instructions, then the dl register (the remainder) is used for the substitution.
Stack Strings
What’s the result in the end?
Merging these obfuscation techniques leads to a nonsense amount of instructions for a basic task, which will obviously burn you some hours of analysis if you don’t take some time for cleaning a bit all that mess with the help of some scripts or plenty other ideas, that could trigger in your mind. It could be nice to see these days some scripts released by the community.
Simple tricks lead to nonsense code
Anti-Debug
There are plenty of techniques abused here that was not in the first analysis, this is not anymore a simple PEB.BeingDebugged or checking if you are running a virtual machine, so let’s dig into them. one per one except CheckRemoteDebugger! This one is enough to understand by itself :’)
NtSetInformationThread
One of the oldest tricks in windows and still doing its work over the years. Basically in a very simple way (because there is a lot thing happening during the process), NtSetInformationThread is called with a value (0x11) obfuscated by a XOR operator. This parameter is a ThreadInformationClass with a specific enum called ThreadHideFromDebugger and when it’s executed, the debugger is not able to catch any debug information. So the supposed pointer to the corresponding thread is, of course, the malware and when you are analyzing it with a debugger, it will result to detach itself.
CloseHandle/NtClose
Inside WinMain, a huge function is called with a lot of consecutive anti-debug tricks, they were almost all indirectly related to some techniques patched by TitanHide (or strongly looks like), the first one performed is a really basic one, but pretty efficient to do the task.
Basically, when CloseHandle is called with an inexistent handle or an invalid one, it will raise an exception and whenever you have a debugger attached to the process, it will not like that at all. To guarantee that it’s not an issue for a normal interaction a simple __try / __except method is used, so if this API call is requested, it will safely lead to the end without any issue.
The invalid handle used here is a static one and it’s L33T code with the value 0xBAADAA55 and makes me bored as much as this face.
That’s not a surprise to see stuff like this from the malware developer. Inside jokes, l33t values, animes and probably other content that I missed are something usual to spot on Predator.
ProcessDebugObjectHandle
When you are debugging a process, Microsoft Windows is creating a “Debug” object and a handle corresponding to it. At this point, when you want to check if this object exists on the process, NtQueryInformationProcess is used with the ProcessInfoClass initialized by 0x1e (that is in fact, ProcessDebugObjectHandle).
In this case, the NTStatus value (returning result by the API call) is an error who as the ID 0xC0000353, aka STATUS_PORT_NOT_SET. This means, “An attempt to remove a process’s DebugPort was made, but a port was not already associated with the process.”. The anti-debug trick is to verify if this error is there, that’s all.
NtGetContextThread
This one is maybe considered as pretty wild if you are not familiar with some hardware breakpoints. Basically, there are some registers that are called “Debug Register” and they are using the DRX nomenclature (DR0 to DR7). When GetThreadContext is called, the function will retrieve al the context information from a thread.
For those that are not familiar with a context structure, it contains all the register data from the corresponding element. So, with this data in possession, it only needs to check if those DRX registers are initiated with a value not equal to 0.
On the case here, it’s easily spottable to see that 4 registers are checked
int 3 (or Interrupt 3) is a popular opcode to force the debugger to stop at a specific offset. As said in the title, this is a breakpoint but if it’s executed without any debugging environment, the exception handler is able to deal with this behavior and will continue to run without any issue. Unless I missed something, here is the scenario.
By the way, as another scenario used for this one (the int 3), the number of this specific opcode triggered could be also used as an incremented counter, if the counter is above a specific value, a simplistic condition is sufficient to check if it’s executed into a debugger in that way.
Debug Condition
With all the techniques explained above, in the end, they all lead to a final condition step if of course, the debugger hasn’t crashed. The checking task is pretty easy to understand and it remains to a simple operation: “setting up a value to EAX during the anti-debug function”, if everything is correct this register will be set to zero, if not we could see all the different values that could be possible.
bloc in red is the correct condition over all the anti-debug tests
…And when the Anti-Debug function is done, the register EAX is checked by the test operator, so the ZF flag is determinant for entering into the most important loop that contains the main function of the stealer.
Anti-VM
The Anti VM is presented as an option in Predator and is performed just after the first C&C requests.
Tricks used are pretty olds and basically using Anti-VM Instructions
SIDT
SGDT
STR
CPUID (Hypervisor Trick)
By curiosity, this option is not by default performed if the C&C is not reachable.
Paranoid & Organized Predator
When entering into the “big main function”, the stealer is doing “again” extra validations if you have a valid payload (and not a modded one), you are running it correctly and being sure again that you are not analyzing it.
This kind of paranoid checking step is a result of the multiple cases of cracked builders developed and released in the wild (mostly or exclusively at a time coming from XakFor.Net). Pretty wild and fun to see when Anti-Piracy protocols are also seen in the malware scape.
Then the malware is doing a classic organized setup to perform all the requested actions and could be represented in that way.
Of course as usual and already a bit explained in the first paper, the C&C domain is retrieved in a table of function pointers before the execution of the WinMain function (where the payload is starting to do tasks).
You can see easily all the functions that will be called based on the starting location (__xc_z) and the ending location (__xc_z).
Then you can spot easily the XOR strings that hide the C&C domain like the usual old predator malware.
Data Encryption & Encoding
Besides using XOR almost absolutely everywhere, this info stealer is using a mix of RC4 encryption and base64 encoding whenever it is receiving data from the C&C. Without using specialized tools or paid versions of IDA (or whatever other software), it could be a bit challenging to recognize it (when you are a junior analyst), due to some modification of some part of the code.
Base64
For the Base64 functions, it’s extremely easy to spot them, with the symbol values on the register before and after calls. The only thing to notice with them, it’s that they are using a typical signature… A whole bloc of XOR stack strings, I believed that this trick is designed to hide an eventual Base64 alphabet from some Yara rules.
By the way, the rest of the code remains identical to standard base64 algorithms.
RC4
For RC4, things could be a little bit messy if you are not familiar at all with encryption algorithm on a disassembler/debugger, for some cases it could be hell, for some case not. Here, it’s, in fact, this amount of code for performing the process.
Blocs are representing the Generation of the array S, then performing the Key-Scheduling Algorithm (KSA) by using a specific secret key that is, in fact, the C&C domain! (if there is no domain, but an IP hardcoded, this IP is the secret key), then the last one is the Pseudo-random generation algorithm (PRGA).
For more info, some resources about this algorithm below:
The Hardware ID (HWID) and mutex are related, and the generation is quite funky, I would say, even if most of the people will consider this as something not important to investigate, I love small details in malware, even if their role is maybe meaningless, but for me, every detail counts no matter what (even the stupidest one).
Here the hardware ID generation is split into 3 main parts. I had a lot of fun to understand how this one was created.
First, it will grab all the available logical drives on the compromised machine, and for each of them, the serial number is saved into a temporary variable. Then, whenever a new drive is found, the hexadecimal value is added to it. so basically if the two drives have the serial number “44C5-F04D” and “1130-DDFF”, so ESI will receive 0x44C5F04D then will add 0x1130DFF.
When it’s done, this value is put into a while loop that will divide the value on ESI by 0xA and saved the remainder into another temporary variable, the loop condition breaks when ESI is below 1. Then the results of this operation are saved, duplicated and added to itself the last 4 bytes (i.e 1122334455 will be 112233445522334455).
If this is not sufficient, the value is put into another loop for performing this operation.
for i, s in enumerate(str):
if i & 1:
a += chr(s) + 0x40
else:
a += chr(s)
It results in the creation of an alphanumeric string that will be the archive filename used during the POST request to the C&C.
the generated hardware ID based on the serial number devices
But wait! there is more… This value is in part of the creation of the mutex name… with a simple base64 operation on it and some bit operand operation for cutting part of the base64 encoding string for having finally the mutex name!
Anti-CIS
A classic thing in malware, this feature is used for avoiding infecting machines coming from the Commonwealth of Independent States (CIS) by using a simple API call GetUserDefaultLangID.
The value returned is the language identifier of the region format setting for the user and checked by a lot of specific language identifier, of courses in every situation, all the values that are tested, are encrypted.
Language ID
SubLanguage Symbol
Country
0x0419
SUBLANG_RUSSIAN_RUSSIA
Russia
0x042b
SUBLANG_ARMENIAN_ARMENIA
Armenia
0x082c
SUBLANG_AZERI_CYRILLIC
Azerbaijan
0x042c
SUBLANG_AZERI_LATIN
Azerbaijan
0x0423
SUBLANG_BELARUSIAN_BELARUS
Belarus
0x0437
SUBLANG_GEORGIAN_GEORGIA
Georgia
0x043f
SUBLANG_KAZAK_KAZAKHSTAN
Kazakhstan
0x0428
SUBLANG_TAJIK_TAJIKISTAN
Tajikistan
0x0442
SUBLANG_TURKMEN_TURKMENISTAN
Turkmenistan
0x0843
SUBLANG_UZBEK_CYRILLIC
Uzbekistan
0x0443
SUBLANG_UZBEK_LATIN
Uzbekistan
0x0422
SUBLANG_UKRAINIAN_UKRAINE
Ukraine
Files, files where are you?
When I reversed for the first time this stealer, files and malicious archive were stored on the disk then deleted. But right now, this is not the case anymore. Predator is managing all the stolen data into memory for avoiding as much as possible any extra traces during the execution.
Predator is nowadays creating in memory a lot of allocated pages and temporary files that will be used for interactions with real files that exist on the disk. Most of the time it’s basically getting handles, size and doing some operation for opening, grabbing content and saving them to a place in memory. This explanation is summarized in a “very” simplify way because there are a lot of cases and scenarios to manage this.
Another point to notice is that the archive (using ZIP compression), is also created in memory by selecting folder/files.
The generated archive in memory
It doesn’t mean that the whole architecture for the files is different, it’s the same format as before.
an example of archive intercepted during the C&C Communication
Stealing
After explaining this many times about how this stuff, the fundamental idea is boringly the same for every stealer:
Check
Analyzing (optional)
Parsing (optional)
Copy
Profit
Repeat
What could be different behind that, is how they are obfuscating the files or values to check… and guess what… every malware has their specialties (whenever they are not decided to copy the same piece of code on Github or some whatever generic .NET stealer) and in the end, there is no black magic, just simple (or complex) enigma to solve. As a malware analyst, when you are starting into analyzing stealers, you want literally to understand everything, because everything is new, and with the time, you realized the routine performed to fetch the data and how stupid it is working well (as reminder, it might be not always that easy for some highly specific stuff).
In the end, you just want to know the targeted software, and only dig into those you haven’t seen before, but every time the thing is the same:
Checking dumbly a path
Checking a register key to have the correct path of a software
Checking a shortcut path based on an icon
etc…
Beside that Predator the Thief is stealing a lot of different things:
Grabbing content from Browsers (Cookies, History, Credentials)
Harvesting/Fetching Credit Cards
Stealing sensible information & files from Crypto-Wallets
Credentials from FTP Software
Data coming from Instant communication software
Data coming from Messenger software
2FA Authenticator software
Fetching Gaming accounts
Credentials coming from VPN software
Grabbing specific files (also dynamically)
Harvesting all the information from the computer (Specs, Software)
Stealing Clipboard (if during the execution of it, there is some content)
Making a picture of yourself (if your webcam is connected)
Making screenshot of your desktop
It could also include a Clipper (as a modular feature).
And… due to the module manager, other tasks that I still don’t have mentioned there (that also I don’t know who they are).
Let’s explain just some of them that I found worth to dig into.
Browsers
Since my last analysis, things changed for the browser part and it’s now divided into three major parts.
Internet Explorer is analyzed in a specific function developed due that the data is contained into a “Vault”, so it requires a specific Windows API to read it.
Microsoft Edge is also split into another part of the stealing process due that this one is using unique files and needs some tasks for the parsing.
Then, the other browsers are fetched by using a homemade static grabber
Grabber n°1 (The generic one)
It’s pretty fun to see that the stealing process is using at least one single function for catching a lot of things. This generic grabber is pretty “cleaned” based on what I saw before even if there is no magic at all, it’s sufficient to make enough damages by using a recursive loop at a specific place that will search all the required files & folders.
By comparing older versions of predator, when it was attempting to steal content from browsers and some wallets, it was checking step by step specific repositories or registry keys then processing into some loops and tasks for fetching the credentials. Nowadays, this step has been removed (for the browser part) and being part of this raw grabber that will parse everything starting to %USERS% repository.
As usual, all the variables that contain required files are obfuscated and encrypted by a simple XOR algorithm and in the end, this is the “static” list that the info stealer will be focused
File grabbed
Type
Actions
Login Data
Chrome / Chromium based
Copy & Parse
Cookies
Chrome / Chromium based
Copy & Parse
Web Data
Browsers
Copy & Parse
History
Browsers
Copy & Parse
formhistory.sqlite
Mozilla Firefox & Others
Copy & Parse
cookies.sqlite
Mozilla Firefox & Others
Copy & Parse
wallet.dat
Bitcoin
Copy & Parse
.sln
Visual Studio Projects
Copy filename into Project.txt
main.db
Skype
Copy & Parse
logins.json
Chrome
Copy & Parse
signons.sqlite
Mozilla Firefox & Others
Copy & Parse
places.sqlite
Mozilla Firefox & Others
Copy & Parse
Last Version
Mozilla Firefox & Others
Copy & Parse
Grabber n°2 (The dynamic one)
There is a second grabber in Predator The Thief, and this not only used when there is available config loaded in memory based on the first request done to the C&C. In fact, it’s also used as part of the process of searching & copying critical files coming from wallets software, communication software, and others…
The “main function” of this dynamic grabber only required three arguments:
The path where you want to search files
the requested file or mask
A path where the found files will be put in the final archive sent to the C&C
When the grabber is configured for a recursive search, it’s simply adding at the end of the path the value “..” and checking if the next file is a folder to enter again into the same function again and again.
In the end, in the fundamentals, this is almost the same pattern as the first grabber with the only difference that in this case, there are no parsing/analyzing files in an in-depth way. It’s simply this follow-up
Find a matched file based on the requested search
creating an entry on the stolen archive folder
setting a handle/pointer from the grabbed file
Save the whole content to memory
Repeat
Of course, there is a lot of particular cases that are to take in consideration here, but the main idea is like this.
What Predator is stealing in the end?
If we removed the dynamic grabber, this is the current list (for 3.3.2) about what kind of software that is impacted by this stealer, for sure, it’s hard to know precisely on the browser all the one that is impacted due to the generic grabber, but in the end, the most important one is listed here.
VPN
NordVPN
Communication
Jabber
Discord
Skype
FTP
WinSCP
WinFTP
FileZilla
Mails
Outlook
2FA Software
Authy (Inspired by Vidar)
Games
Steam
Battle.net (Inspired by Kpot)
Osu
Wallets
Electrum
MultiBit
Armory
Ethereum
Bytecoin
Bitcoin
Jaxx
Atomic
Exodus
Browser
Mozilla Firefox (also Gecko browsers using same files)
Chrome (also Chromium browsers using same files)
Internet Explorer
Edge
Unmentioned browsers using the same files detected by the grabber.
Also beside stealing other actions are performed like:
Performing a webcam picture capture
Performing a desktop screenshot
Loader
There is currently 4 kind of loader implemented into this info stealer
RunPE
CreateProcess
ShellExecuteA
LoadPE
LoadLibrary
For all the cases, I have explained below (on another part of this analysis) what are the options of each of the techniques performed. There is no magic, there is nothing to explain more about this feature these days. There are enough articles and tutorials that are talking about this. The only thing to notice is that Predator is designed to load the payload in different ways, just by a simple process creation or abusing some process injections (i recommend on this part, to read the work from endgame).
Module Manager
Something really interesting about this stealer these days, it that it developed a feature for being able to add the additional tasks as part of a module/plugin package. Maybe the name of this thing is wrongly named (i will probably be fixed soon about this statement). But now it’s definitely sure that we can consider this malware as a modular one.
When decrypting the config from check.get, you can understand fast that a module will be launched, by looking at the last entry…
This will be the name of the module that will be requested to the C&C. (this is also the easiest way to spot a new module).
example.get
example.post
The first request is giving you the config of the module (on my case it was like this), it’s saved but NOT decrypted (looks like it will be dealt by the module on this part). The other request is focused on downloading the payload, decrypting it and saving it to the disk in a random folder in %PROGRAMDATA% (also the filename is generated also randomly), when it’s done, it’s simply executed by ShellExecuteA.
Also, another thing to notice, you know that it’s designed to launch multiple modules/plugins.
Clipper (Optional module)
The clipper is one example of the Module that could be loaded by the module manager. As far as I saw, I only see this one (maybe they are other things, maybe not, I don’t have the visibility for that).
Disclaimer: Before people will maybe mistaken, the clipper is proper to Predator the Thief and this is NOT something coming from another actor (if it’s the case, the loader part would be used).
Clipper WinMain function
This malware module is developed in C++, and like Predator itself, you recognized pretty well the obfuscation proper to it (Stack strings, XOR, SUB, Code spaghetti, GetProcAddress recreated…). Well, everything that you love for slowing down again your analysis.
As detailed already a little above, the module is designed to grab the config from the main program, decrypting it and starting to do the process routine indefinitely:
Open Clipboard
Checking content based on the config loaded
If something matches put the malicious wallet
Sleep
Repeat
The clipper config is rudimentary using “|” as a delimiter. Mask/Regex on the left, malicious wallet on the right.
There is no communication with the C&C when the clipper is switching wallet, it’s an offline one.
Self Removal
When the parameters are set to 1 in the Predator config got by check.get, the malware is performing a really simple task to erase itself from the machine when all the tasks are done.
By looking at the bottom of the main big function where all the task is performed, you can see two main blocs that could be skipped. these two are huge stack strings that will generate two things.
the API request “ShellExecuteA”
The command “ping 127.0.0.1 & del %PATH%”
When all is prepared the thing is simply executed behind the classic register call. By the way, doing a ping request is one of the dozen way to do a sleep call and waiting for a little before performing the deletion.
This option is not performed by default when the malware is not able to get data from the C&C.
Telemetry files
There is a bunch of files that are proper to this stealer, which are generated during the whole infection process. Each of them has a specific meaning.
Information.txt
Signature of the stealer
Stealing statistics
Computer specs
Number of users in the machine
List of logical drives
Current usage resources
Clipboard content
Network info
Compile-time of the payload
Also, this generated file is literally “hell” when you want to dig into it by the amount of obfuscated code.
I can quote these following important telemetry files:
Software.txt
Windows Build Version
Generated User-Agent
List of software installed in the machine (checking for x32 and x64 architecture folders)
Actions.txt
List of actions & telemetry performed by the stealer itself during the stealing process
Projects.txt
List of SLN filename found during the grabber research (the static one)
CookeList.txt
List of cookies content fetched/parsed
Network
User-Agent “Builder”
Sometimes features are fun to dig in when I heard about that predator is now generating dynamic user-agent, I was thinking about some things but in fact, it’s way simpler than I thought.
The User-Agent is generated in 5 steps
Decrypting a static string that contains the first part of the User-Agent
Using GetTickCount and grabbing the last bytes of it for generating a fake builder version of Chrome
Decrypting another static string that contains the end of the User-Agent
Concat Everything
Profit
Tihs User-Agent is shown into the software.txt logfile.
C&C Requests
There is currently 4 kind of request seen in Predator 3.3.2 (it’s always a POST request)
Request
Meaning
api/check.get
Get dynamic config, tasks and network info
api/gate.get ?……
Send stolen data
api/.get
Get modular dynamic config
api/.post
Get modular dynamic payload (was like this with the clipper)
The first step – Get the config & extra Infos
For the first request, the response from the server is always in a specific form :
String obviously base64 encoded
Encrypted using RC4 encryption by using the domain name as the key
When decrypted, the config is pretty easy to guess and also a bit complex (due to the number of options & parameters that the threat actor is able to do).
[0;1;0;1;1;0;1;1;0;512;]#[[%userprofile%\Desktop|%userprofile%\Downloads|%userprofile%\Documents;*.xls,*.xlsx,*.doc,*.txt;128;;0]]#[Trakai;Republic of Lithuania;54.6378;24.9343;85.206.166.82;Europe/Vilnius;21001]#[]#[Clipper]
It’s easily understandable that the config is split by the “#” and each data and could be summarized like this
The stealer config
The grabber config
The network config
The loader config
The dynamic modular config (i.e Clipper)
I have represented each of them into an array with the meaning of each of the parameters (when it was possible).
Predator config
Args
Meaning
Field 1
Webcam screenshot
Field 2
Anti VM
Field 3
Skype
Field 4
Steam
Field 5
Desktop screenshot
Field 6
Anti-CIS
Field 7
Self Destroy
Field 8
Telegram
Field 9
Windows Cookie
Field 10
Max size for files grabbed
Field 11
Powershell script (in base64)
Grabber config
[]#[GRABBER]#[]#[]#[]
Args
Meaning
Field 1
%PATH% using “|” as a delimiter
Field 2
Files to grab
Field 3
Max sized for each file grabbed
Field 4
Whitelist
Field 5
Recursive search (0 – off | 1 – on)
Network info
[]#[]#[NETWORK]#[]#[]
Args
Meaning
Field 1
City
Field 2
Country
Field 3
GPS Coordinate
Field 4
Time Zone
Field 5
Postal Code
Loader config
[]#[]#[]#[LOADER]#[]
Format
[[URL;3;2;;;;1;amazon.com;0;0;1;0;0;5]]
Meaning
Loader URL
Loader Type
Architecture
Targeted Countries (“,” as a delimiter)
Blacklisted Countries (“,” as a delimiter)
Arguments on startup
Injected process OR Where it’s saved and executed
Pushing loader if the specific domain(s) is(are) seen in the stolen data
Pushing loader if wallets are presents
Persistence
Executing in admin mode
Random file generated
Repeating execution
???
Loader type (argument 2)
Value
Meaning
1
RunPE
2
CreateProcess
3
ShellExecute
4
LoadPE
5
LoadLibrary
Architecture (argument 3)
Value
Meaning
1
x32 / x64
2
x32 only
3
x64 only
If it’s RunPE (argument 7)
Value
Meaning
1
Attrib.exe
2
Cmd.exe
3
Audiodg.exe
If it’s CreateProcess / ShellExecuteA / LoadLibrary (argument 7)
This is an example of crafted request performed by Predator the thief
Third step – Modular tasks (optional)
/api/Clipper.get
Give the dynamic clipper config
/api/Clipper.post
Give the predator clipper payload
Server side
The C&C is nowadays way different than the beginning, it has been reworked with some fancy designed and being able to do some stuff:
Modulable C&C
Classic fancy index with statistics
Possibility to configure your panel itself
Dynamic grabber configuration
Telegram notifications
Backups
Tags for specific domains
Index
The predator panel changed a lot between the v2 and v3. This is currently a fancy theme one, and you can easily spot the whole statistics at first glance. the thing to notice is that the panel is fully in Russian (and I don’t know at that time if there is an English one).
Menu on the left is divide like this (but I’m not really sure about the correct translation)
In term of configuring predator, the choices are pretty wild:
The actor is able to tweak its panel, by modifying some details, like the title and detail that made me laugh is you can choose a dark theme.
There is also another form, the payload config is configured by just ticking options. When done, this will update the request coming from check.get
As usual, there is also a telegram bot feature
Creating Tags for domains seen
Small details which were also mentioned in Vidar, but if the actor wants specific attention for bots that have data coming from specific domains, it will create a tag that will help him to filter easily which of them is probably worth to dig into.
C and C++ binaries share several commonalities, however, some additional features and complexities introduced by C++ can make reverse engineering C++ binaries more challenging compared to C binaries. Some of the most important features are:
Name Mangling: C++ compilers often use name mangling to encode additional information about functions and classes into the symbol names in the binary. This can make it more challenging to understand the code’s structure and functionality by simply looking at symbol names.
Object-Oriented Features: C++ supports object-oriented programming (OOP) features such as classes, inheritance, polymorphism, and virtual functions. Reverse engineering C++ binaries may involve identifying and understanding these constructs, which may not exist in C binaries.
Templates: C++ templates allow for generic programming, where functions and classes can operate on different data types. Reverse engineering C++ templates can be complex due to the generation of multiple versions of the same function or class template with different types.
Another topic that is mandatory to understand when we approach binaries is related to the calling convention. Even if it’s determined by the operating system and the compiler ABI (Application Binary Interface) rather than the specific programming language being used, its one of the fundamental aspects that too many times is overlooked.
💡There are many other differences related to Runtime Type Information (RTTI), Constructor and Destructor Calls, Exception Handling and Compiler-Specific Features. Those topics aren’t less important than the others mentioned above, however, explaining a basic triage does not involve those topics and giving an explanation for all of them could just lose the focus. Moreover, If you don’t feel comfortable with calling conventions, refer to exceptional material on OALabs.
Why GlorySprout?
I know, probably this name for most of you does not mean anything because it does not represent one the most prominent threats on Cyberspace, however, didactically speaking, it has a lot of characteristics that make it a great fit. First of all it’s a recent malware and because of this, it shares most of the capabilities employed by more famous ones such as: obfuscation, api hashing, inline decryption etc.. Those characteristics are quite challenging to deal with, especially if we go against them to build an automation script that is going to replicate our work on multiple samples.
Another interesting characteristic of this malware is that it represents a fork of another malware called Taurus Stealer as reported by RussianPanda in her article. So, why is it important? Taurus Stealers have been dissected and a detailed report is available here. From a learning stand point it represents a plus, since if you are stuck somewhere in the code, you have a way out trying to match this GlorySprout capabilities with Taurus.
Let’s start our triage.
Binary Overview
Opening up the binary in IDA and scrolling a little bit from the main functions it should be clear that this binary is going to use some api hashing for retrieving DLLs, inline decryption and C++ structures to store some interesting value. To sum up, this binary is going to start resolving structures and APIs, perform inline decryption to start checking Windows information and installed softwares. However, those actions are not intended to be taken without caution. In fact, each time a string is decrypted, its memory region is then immediately zeroed after use. It means that a “quick and dirty” approach using dynamic analysis to inspect memory sections won’t give you insights about strings and/or targets.
Figure 1: Binary Overview
Identifying and Creating Structures
Identifying and creating structures is one of the most important tasks when we deal with C++ malware. Structures are mostly reused through all code, because of that, having a good understanding of structures is mandatory for an accurate analysis. In fact, applying structures properly will make the whole reversing process way more easier.
Now you may be wondering, how do we recognise a structure? In order to recognise structures it’s important to observe how a function is called and how input parameters are actually used.
In order to explain it properly, let’s take an example from GlorySprout.
Figure 2: Passing structure parameter
Starting from left to right, we see some functions callings that could help us to understand that we are dealing with a structure. Moreover, its also clear in this case, how big the structures is.
💡As said before, calling convention is important to understand how parameters are passed to a function. In this case, we are dealing with is a clear example of thiscall.
Let’s have a look at the function layout. Even if we are seeing that ecx is going to be used as a parameter for three functions, it is actually used each time with a different offset (this is a good indication that we are dealing with a structure). Moreover, if we have a look at the first call (sub_401DEB), this function seems to fill the first 0xF4 (244 in decimal) bytes pointed by ecx with some values. Once the function ends, there is the instruction lea ecx, [esi+0F8h] and another function call. This pattern is used a couple of times and confirms our hypothesis that each function is in charge to fill some offset of the structure.
From the knowledge we have got so far and looking at the code, we could also infer the structure passed to the third call (sub_406FF1) and the whole size of the structure.
sub_406FF1_bytes_to_fill = 0xF8 - 0x12C = 0x34 (52 bytes)
structure_size = 0xF8 + 0x34 = 0x12C (300 bytes) + 4 bytes realted to the size of the last value.
PowerShell
However, even if we resolved the size structures and understood where it is used, there is still a point missing. Where does this structure come from? To answer this question, it’s important to take a step back. Looking at the functionsub_40100A we see the instruction [mov ecx , offset unk_4463F8]. If you explore that variable you will see that it is stored at 0x004463F8 and the next variable is stored at 0x0044652F. If we do a subtraction through these two addresses, we have 312 bytes. There are two important things to highlight here. First of all, we are dealing with a global structure that is going to be used multiple times in different code sections (because of that, naming structure fields will be our first task), however, according to the size calculated, it seems that we are missing a few bytes. This could be a good indication that additional bytes will be used later on in the code to store an additional value. In fact, this insight is confirmed if we analyze the last function (sub_40B838). Opening up the function and skipping the prolog instructions, we could immediately see that the structure is moved in esi, and then a dword is moved to esi+4. It means that esi is adding 4 bytes to the structure that means that now the structure size is 308 bytes.
Figure 3: Understanding structure size
Now that we have a better understanding of the structure’s size, it’s time to understand its values. In order to figure out what hex values represent, we need to go a little bit deeper exploring the function. Going over a decryption routine, there is a call towards sub_404CC1. If we follow this call, we should immediately recognize a familiar structure (if not, have a look at this article). We are dealing with a routine that is going to resolve some APIs through the hex value passed to the function.
Figure 4: PEB and LDR data to collect loaded DLLs
Well, so far we have all the elements required to solve our puzzle! The structure we are dealing with is 312 bytes long and contains hex values related to APIs. Doing an educated guess, these values will be used and resolved on the fly, when a specific API function is required (structure file will be shared in the Reference section).
💡As part of the triage process, structures are usually the very first block of the puzzle to solve. In this case, we have seen a global structure that is stored within the data section. Exploring the data section a little bit deeper, you will find that structures from this sample are stored one after another. This could be a very good starting point to resolve structures values and hashes that could highlight the binary capabilities.
Resolving API Hash
If we recall Figure 3, we see multiple assignment instructions related to esi that contain our structure. Then in Figure 4 we discovered that API hashing routine is applied to some hex to get a reference to the corresponding function. The routine itself is quite easy and standard, at least in terms of retrieving the function name from the DLL (a detailed analysis has been done here).
Figure 5: API hashing routine
The Figure above, represents the routine applied to each function name in order to find a match with the hash passed as input. It should be easy to spot that esi contains (on each iteration) a string character that will be manipulated to produce the corresponding hash.
💡The routine itself does not require a lot of explanation and it’s pretty easy to reconstruct. In order to avoid any spoilers, if a reader wants to take this exercise, my code will be shared within the Reference section. It’s worth mentioning that this function could be implemented also through emulation, even if code preparation is a bit annoying compared to the function complexity, it could be a good exercise too.
Inline Decryption
So far we have done good work reconstructing structure layout and resolving API. That information gave us few insights about malware capabilities and in general, what could be the actions taken by this malware to perform its tasks. Unfortunately, we have just scratched the surface. In fact we are still missing information about malware configuration, such as: targets, C2, anti-debug, etc.. In fact, most of the interesting strings are actually decrypted with an inline routine.
💡For anyone of you that actually tried to analyze this malware, you should already familiar with inline decryption routine, since that it spread all around the code.
Inline decryption is a quite interesting technique that really slows down malware analysis because it requires decryption of multiple strings, usually with slight differences, on the fly. Those routines are all over the code and most of the malware actions involve their usage. An example has been already observed in Figure 4 and 5. However, in order to understand what we are talking about, The figure below show some routines related to this technique:
Figure 6: Inline Decryption
As you can see, all those routines are quite different, involving each time a different operand and sometimes, the whole string is built on multiple parts of the code. According to the information collected so far, about inline decryption, it should be clear that creating a script for each routine will take forever. Does it end our triage? Likely, we still have our secret weapon called emulation.
The idea to solve this challenge is quite simple and effective, but it requires a little bit of experience: Collect all strings and their decryption routine in order to properly emulate each snippet of code.
Automation
Automating all the inlineencryption and the hashing routine it’s not an easy task. First of all, we need to apply the evergreen approach of “dividi et impera”.In this way, the hashing routine have been partially solved using the template from a previous post. In this way, it’s just a matter of rewriting the function and we are going to have all the corresponding matches.
Figure 7: advapi32.dll resolved hashes
However, what is really interesting in this sample is related to the string decryption. The idea is quite simple but very effective. First of all, in order to emulate this code, we need to identify some structures that we could use as anchor that is going to indicate that the decryption routine ended. Then we need to jump back to the very first instruction that starts creating the stack string. Well, it is easier said than done, because jumping back in the middle of an instruction and then going forward to the anchor value would lead us to an unpredictable result. However, if we jump back, far enough from the stack string creation, we could traverse the instructions upside down, starting from the anchor value back to the stack string. Doing so won’t lead to any issue, since all instructions are actually correct.
Figure 8: Resolved strings
Conclusion
Through this post we have started to scratch the surface of C++ binaries, understanding calling conventions and highlighting some features of those binaries (e.g, classes and calling conventions). However, going further would have been confusing, providing too much details on information that wouldn’t have an immediate practical counterpart. Nevertheless, what was quite interesting regardless of the api hashing routine emulation, was the inline decryption routine, introducing the idea of anchors and solving the issue of jumping back from an instruction.
In this interview, Butcher talks about the motivation and evolution of serverless functions and how Wasm complements it. He touches upon the use cases of Wasm in edge computing, AI and also on the server.
He also spoke about how SpinKube, recently introduced as a serverless platform on the Kubernetes platform powered by Wasm, was an effort motivated by the adoption of Kubernetes based on a similar orchestrator that was used in the Fermyon Cloud. Finally, Butcher paints a realistic picture of the challenges to the Wasm community especially with the existing communities such as Java.
Can you please introduce yourself, and provide a brief background as to how Wasm came about? Any particular pain point in distributed systems app development that you were intent on solving with Wasm?
I spent my career in software at the intersection of distributed computing, developer tooling, and supply chain security; it wasn’t really one benefit that drew me to Wasm, but how the characteristics of the technology mapped to the problems I was trying to solve (and more generally, the problems we’ve been trying to solve as an industry): portability; startup and execution speed; strong capability-based sandboxing; and artifact size.
At Microsoft, we were looking at Azure Functions and other similar technologies and were seeing a lot of waste. Systems were sitting idle 80% (or more) just waiting for inbound requests. Virtual machines were sitting pre-warmed in a queue consuming memory and CPU, waiting to have a serverless function installed and executed. And all this wastage was done in the name of performance. We asked ourselves: What if we could find a much more efficient form of compute that could cold start much faster? Then we wouldn’t have to pre-warm virtual machines. We could drastically improve density, also, because resources would be freed more often.
So it was really all about finding a better runtime for the developer pattern that we call “serverless functions.” There are too many definitions of serverless floating around. When we at Fermyon say that, we mean the software design pattern in which a developer does not write a server, but just an event handler. The code is executed when a request comes in and shuts down as soon as the request has been handled.
Yes. The first generation of serverless gave us a good design pattern (FaaS, or serverless functions) based on event handling. But from Lambda to KNative, the implementations were built atop runtimes that were not optimized for that style of workload. Virtual machines can take minutes to start, and containers tend to take a few dozen seconds. That means you either have to pre-warm workloads or take large cold-start penalties. Pre-warming is costly, involving paying for CPU and memory while something sits idle. Cold starts, though, have a direct user impact: slow response time.
We were attracted to WebAssembly specifically because we were looking for a faster form of compute that would reduce cold start time. And at under one millisecond, WebAssembly’s cold start time is literally faster than the blink of an eye. But what surprised us was that by reducing cold start, utilizing WebAssembly’s small binary sizes, and writing an effective serverless functions executor, we have been able to also boost density. That, in turn, cuts cost and improves sustainability since this generation of serverless is doing more with fewer resources.
Delving into the intersection of Wasm and edge computing, Is Wasm primarily tailored for edge applications where efficiency and responsiveness are paramount?
Serverless functions are the main way people do edge programming. Because of its runtime profile, Wasm is a phenomenal fit for edge computing — and we have seen content delivery networks like Fastly, and more recently Cloudflare, demonstrate that. And we are beginning to see more use cases of Wasm on constrained and disconnected devices — from 5G towers to the automotive industry (with cars running Spin applications because of that efficiency and portability).
One way to think about this problem is in terms of how many applications you can run on an edge node. Containers require quite a bit of system resources. On a piece of hardware (or virtual machine) that can run about 30-50 containers, we can run upwards of 5,000 serverless Wasm apps. (Fermyon Cloud runs 3,000 user apps per node on our cluster.)
The other really nice thing about WebAssembly is that it is OS- and architecture-neutral. It can run on Windows, Linux, Mac, and even many exotic operating systems. Likewise, it can execute on Intel architecture or ARM. That means the developer can write and compile the code without having to know what the destination is. And that’s important for edge computing where oftentimes the location is decided at execution time.
Navigating the realm of enterprise software: Many enterprises still use Java. Keeping Java developers and architects in mind, can you compare and contrast Java and Wasm? Can you talk about the role of WASI in this context?
Luke Wagner, the creator of Wasm, once said to me that Java broke new ground (along with .NET) in the late 90s and over decades they refined, optimized, and improved. WebAssembly was an opportunity to start afresh on a foundation of 20 years of research and development.
Wasm is indebted to earlier bytecode languages, for sure. But there’s more to it than that. WebAssembly was built with very stringent security sandboxing needs. Deny-by-default and capabilities-based system interfaces are essential to a technology that assumes it is running untrusted code. Java and .NET take the default disposition that the execution context can “trust” the code it is running. Wasm is the opposite.
Secondly, Wasm was built with the stated goal that many different languages (ideally any language) can be compiled to Wasm. JVM and .NET both started from a different perspective that specific languages would be built to accommodate the runtime. In contrast, the very first language to get Wasm support was C. Rust, Go, Python, and JavaScript all followed along soon after. In other words, WebAssembly demonstrated that it could be a target for existing programming languages while after decades neither Java nor .NET have been able to do this broadly.
Moreover, WebAssembly was designed for speed both in terms of cold start and runtime performance. While Java has always had notoriously slow startup times, WebAssembly binaries take less than a millisecond to cold start.
But the greatest thing about WebAssembly is that if it is actually successful, it won’t be long until both Java and .NET can compile to WebAssembly. The .NET team has said they’ll fully support WebAssembly late in 2024. Hopefully, Java won’t be too far behind.
Exploring the synergy between Wasm and Kubernetes, SpinKube was released at the Cloud Native Computing Foundation‘s Kubecon EU 2024 in Paris. Was Kubernetes an afterthought? How does it impact cloud native app development including addressing deficiencies, and redefining containerized applications?
Most of us from Fermyon worked in Kubernetes for a long time. We built Helm, Brigade, OAM, OSM, and many other Kubernetes projects. When we switched to WebAssembly, we knew we’d have to start with developer tools and work our way toward orchestrators. So we started with Spin to get developers building useful things. We built Fermyon Cloud so that developers would be able to deploy their apps to our infrastructure. Behind the scenes, Fermyon Cloud runs HashiCorp’s Nomad. It has been a spectacular orchestrator for our needs. As I said earlier, we’ve been able to host 3,000 user-supplied apps per worker node in our cluster, orders of magnitude higher than what we could have achieved with containers.
But inevitably we felt the pull of Kubernetes’ gravity. So many organizations are operating mature Kubernetes clusters. It would be hard to convince them to switch to Nomad. So we worked together with Microsoft, SUSE, Liquid Reply, and others to build an excellent Kubernetes solution. Microsoft did some of the heaviest lifting when they wrote the containerd support for Spin.
SpinKube’s immediate popularity surprised even us. People are eager to try a serverless runtime that outperforms Knative and other early attempts at serverless in Kubernetes.
Let’s chat about Wasm and Artificial Intelligence. There’s a buzz about Wasm and AI. Can you expand on this? Does this mean that Large Language Models (LLMs), etc. can be moved to the edge with Wasm?
There are two parts to working with LLMs. There’s training a model, which takes huge amounts of resources and time. And there’s using (or “inferring against”) a model. This later part can benefit a lot from runtime optimization. So we have focused exclusively on serverless inferencing with LLMs.
At its core, WebAssembly is a compute technology. We usually think of that in terms of CPU usage. But it’s equally applicable to the GPUs that AI uses for inferencing. So we have been able to build SDKs inside of the WebAssembly host that allow developers to do LLM inferencing without having to concern themselves with the underlying GPU architecture or resources.
Most importantly, Fermyon makes it possible to time-slice GPU usage at a very fine level of granularity. While most AI inferencing engines lock the GPU for the duration of a server process (e.g. hours, days, or months at a time), we lock the GPU only during an inferencing operation, which is seconds or maybe a few minutes at a time. This means you can get much higher density, running more AI applications on the same GPU.
This is what makes Wasm viable on the edge, where functions run for only a few eye blinks. Those edge nodes will need only a modest number of GPUs to serve thousands of applications.
WASM roadmap: What are the gaps hampering Wasm adoption and the community-driven roadmap to address them? Anything else you want to add?
WebAssembly is still gaining new features. The main one in flight right now is asynchronous function calls across components. This would allow WebAssembly modules to talk to each other asynchronously, and this will vastly improve the parallel computing potential of Wasm.
But always the big risk with WebAssembly comes from its most audacious design goal. Wasm is only successful if it can run all major programming languages, and run them in a more or less uniform way (e.g. with support for WASI, the WebAssembly System Interface). We’ve seen many languages add first-tier WebAssembly support. Some have good implementations that are not included in the main language and require separate toolchains. That’s a minor hindrance. Others, like Java, haven’t made any notable progress. While I think things are progressing well for all major languages other than Java, until those languages have complete support, they have not reached their full potential.
Imagine this: you are working in a company named DonutGPT as Head of Platform Engineering, and you sell millions of donuts online every year with AI-generated recipes. You need to make your critical services available to hundreds of resellers through secured APIs. Since nobody on earth wants to see his donut order fail, your management is putting on the pressure to ensure a highly available service.
Your current production environment consists mostly of VMs, but you are in the process of progressively migrating to a cloud native platform. Most of the production services you handle expose APIs, but your team has very little control and visibility over them. Each service is owned by a different developer team, and there is no consistency in languages, deployed artifacts, monitoring, observability, access control, encryption, etc.
Some services are Java-based, “secured” with old TLS 1.1 certificates, and behind a JWT access control policy. Other services are Python-based, use TLS 1.3 certificates, and are behind a custom-made access control policy. This diversity can be extended to the rest of the services in your production environment.
You (reasonably) think that this situation is far from ideal, and you plan to rationalize APIs at DonutGPT with the help of an API Management solution. Your requirements include:
Your APIs should be strongly governed with centralized and consistent security policies
You need advanced traffic management like rate limiting or canary releases
You need real-time observability and usage metrics on all public endpoints
Simply put, you want predictable operations, peace of mind, and better sleep.
It looks like your plan is right, and you are on track for better days (or nights). However, an API journey is long, and the road ahead is full of obstacles. Here are the top five worst anti-patterns you should avoid when you start your API odyssey.
Anti-Pattern 1: Monolith-Microservices
You are about to invest time, money, and effort in setting up an API management solution. In this process, you will centralize many aspects of your exposed services like traffic management, connectivity security, and observability. It’s easy to think, “The more centralized everything is, the more control I have, and the better I will sleep.” Why not use this API management solution to intercept every API call and transform the HTTP body to sanitize it from sensitive data (like private information)?
This would ensure that every API call is clean across the whole system. That’s true, but only in the short term.
Let’s fast forward three years. Your API management platform is now mature and manages hundreds of APIs across dozens of different teams. The initial quick win to sanitize the HTTP body within the API management workflow gradually became a white elephant:
The first quick patch inevitably evolved into more complex requirements, needing to be adapted to every API. Your ten stylish lines of code quickly grow to an unmaintainable 5000-line script.
No one wants to take ownership of this custom script now that it operates many teams’ APIs
Every new version of an API may require updating and testing this piece of code, which is located in the API platform and separated from the services’ code repositories.
It takes a lot of work to test this custom script. If you have any issues, you will first learn of them from live traffic, and you will have a hard time debugging it.
Your API solution is highly resource-intensive. You should avoid delegating the whole HTTP body to your reverse proxy. This consumes most of the CPU allocated to your platform, giving you very little margin for security while making it a super expensive approach.
In short, it’s best to avoid short-term decision-making. What seems like a good idea at the time may not hold up several years down the road. API management is designed to discover, secure, organize, and monitor your APIs. It should not be used as a shortcut to execute application code.
→ Separation of concern is critical when designing your next production platform.
Anti-Pattern 2: Cart Before the Horse
Another interesting anti-pattern is a laser focus on the long-term, possibly idealized, outcome without recognizing or understanding the steps to get there. Your API transformation project is so expensive you want to ensure everything runs smoothly. So, you choose the most feature-rich API management solution to cover all possible future needs despite being unable to take most of its capabilities today.
Sure, it’s more expensive, but it’s a safe bet if it prevents you from a potential migration in three years. This may seem risk-free, but you only see the tip of the API project iceberg.
Fast forward three years with this top-notch & expensive solution:
The transition from the legacy platform took way longer than expected.
This new solution required paid training sessions from the vendor for your team and many developers throughout the company
You STILL have yet to use many features of the solution.
Many developer teams avoided adopting this new platform due to its complexity.
Your initial goal of controlling all API calls within the company has yet to be reached.
You still have inadequate sleep.
At this point, you acknowledge that the most complete (and complex) solution might not be the best option, so you bite the bullet and decide to migrate to a simpler solution that fits your existing needs. In your attempt to avoid an API management migration three years after starting your project, you ended up causing it anyway, only sooner than initially anticipated.
The point here is that while you should aim for your long-term vision (and choose a solution that aligns with it), address your needs today and strategically build towards that vision. This includes planning for progressive training and adoption by the teams. If the product cannot provide you with a progressive learning curve and deployment journey, then you won’t be able to stick to your plan.
Here is an example of a progressive journey with the same product:
Start small with basic ingress resources on Kubernetes.
Then, an API Gateway will be introduced that brings API traffic management and security.
Then, after you have a much better understanding of the features that are important for your business, transition to an API management platform.
In a nutshell, don’t pick a product because of all the bells and whistles. No amount of cool features will solve your challenges if they never get used. Evaluate them based on what it’s like to use to meet your needs today and whether or not they provide a progressive transition to more advanced use cases in the future.
→ Don’t get ahead when transitioning to your API management platform.
Anti-Pattern 3: Good Enough as Code
As a modern Head of Platform Engineering, you strongly believe in Infrastructure as Code (IaC). Managing and provisioning your resources in declarative configuration files is a modern and great design pattern for reducing costs and risks. Naturally, you will make this a strong foundation while designing your infrastructure.
During your API journey, you will be tempted to take some shortcuts because it can be quicker in the short term to configure a component directly in the API management UI than setting up a clean IaC process. Or it might be more accessible, at first, to change the production runtime configuration manually instead of deploying an updated configuration from a Git commit workflow. Of course, you can always fix it later, but deep inside, those kludges stay there forever.
Or worse, your API management product needs to provide a consistent IaC user experience. Some components need to be configured in the UI. Some parts use YAML, others use XML, and you even have proprietary configuration formats. These diverse approaches make it impossible to have a consistent process.
You say, “Infrastructure as a Code is great, but exceptions are ok. Almost Infrastructure as a Code is good enough.”
Fast forward three years:
60% of the infrastructure is fully declared in configuration files and sits in a git repository
Those configuration files are written in five formats: YAML, INI, XML, JSON, and a custom format.
The remaining 40% requires manual operations in some dashboards or files.
There is such diversity in configuration formats or processes that your team is unable to get the platform under control and constantly needs to be rescued by other teams that have knowledge of each format or process.
Human error is so high that your release process is prolonged and unreliable. Any change to the infrastructure requires several days to deploy in production, and this is the best-case scenario.
In the worst-case scenario, a change is deployed in production, creating a major outage. As your team is not able to troubleshoot the issue quickly, the time to recovery is measured in hours. Your boss anxiously looks at the screen over your shoulder, waiting for the miraculous fix to be deployed. Thousands of donut orders are missed in the process.
You don’t even try to sleep tonight.
The conclusion is obvious — setting up API Management partially as code defeats the purpose of reducing costs and risks. It’s only when your API Management solution is 100% as code that you can benefit from a reliable platform, a blazing fast time to market, and fast recovery.
Exceptions to the process will always bring down your platform’s global efficiency and reliability.
→ Never settle for half-baked processes.
Anti-Pattern 4: Chaotic Versioning System
When you start your API journey, planning for and anticipating every use case is difficult. Change is inevitable, but how you manage it is not. As we’ll see in this section, the effects of poor change management can snowball over the years.
Let’s go back to the very beginning: You are launching your brand new API platform and have already migrated hundreds of APIs into production. You are pretty happy with the results; you feel under control and are getting better sleep.
After one year, your state-of-the-art monitoring alerts flood your notifications, pointing to a bunch of API calls from one of your biggest customers with 404 errors. 404 errors are widespread, so you pay little attention to them and quickly forward the issue to the developer team in charge of the API.
During the following months, you see the number of 404 errors and 500 errors rising significantly, affecting dozens of different APIs. You start to feel concerned about this issue and gather your team to troubleshoot and find the root cause.
Your analysis uncovers a more significant problem: your APIs need a consistent versioning system. You designed your platform as if your API contracts would never change, as if your APIs would last forever.
As a result, to handle change management and release new versions of their APIs, each team followed the processes:
Some teams did not bother dealing with compatibility checks and kept pushing breaking changes.
Some teams tried to keep their APIs backward compatible at all costs. Not only did this make the codebase a nightmare to maintain, but it slowly became obvious that it discouraged teams from innovating, as they wanted to avoid breaking changes and maintaining compatibility with all versions.
Some teams followed a more robust process with the use of URL versioning, like https://donutgpt.com/v1/donuts and https://donutgpt.com/v2/donuts. They were able to maintain multiple versions at the same time, with different codebases for each version. The problem was that other teams were using different strategies, like query parameter versioning (https://donutgpt.com/donuts?version=v1) or even header versioning.
Some teams consistently followed a specific versioning strategy like URL versioning but did not provide versioned documentation.
This study makes you realize how creative the human brain is — the developers chose so many different options!
The result is that customers were:
Using outdated documentation
Calling outdated or dead APIs
Calling different APIs with different versioning strategies
Calling unreliable APIs
Receiving donuts with your new “experimental recipe” when they ordered your classic “Legend GPT Donut”
The key takeaways are apparent: No code lasts forever, and change is a natural part of API development. Given this truth, you must have a strong, reliable, and repeatable foundation for your release process and API lifecycle management.
Your choice of API management solution can help, too. Choose a solution that provides a flexible versioning strategy that fits your needs and can be enforced on every API of DonutGPT.
Additionally, ensure teams maintain several versions of their APIs that can be easily accessible as part of a broader change management best practice. This is the only way to maintain a consistent and reliable user experience for your customers.
→ Enforce a uniform versioning strategy for all your APIs.
Anti-Pattern 5: YOLO Dependencies Management
Now that you’ve learned why managing your API versioning strategy is critical, let’s discuss dependency management for APIs — a topic that is often highly underestimated for a good reason. It’s pretty advanced.
After the miserable no-versioning-strategy episode, you were reassured to see versioning policies enforced on every piece of code at DonutGPT. You were even starting to sleep better, but if you’ve read this far, you know this can’t last.
After two more months, your state-of-the-art monitoring again alerts you to several API calls from one of your biggest customers, resulting in 404 errors! You’ve got to be kidding me! You know the rest of the story: task force, troubleshooting, TooManyDonutsErrors, root cause analysis, and (drum roll) …
All your APIs indeed followed the enforced versioning strategy: https://donutgpt.com/v1/donuts. So, what happened?
This was only enforced on the published routes on the API management platform. The services behind the APIs were following a different versioning strategy. Even for those few, there was no dependency management between your API routes and backend services.
In other words, https://donutgpt.com/v1/donuts and https://donutgpt.com/v2/donuts were able to call the same version of a service, which led to a situation similar to the no-versioning-strategy episode, with a terrible customer experience. It gets even more complex if some services call other services.
You start to see my point: you need dependency policies enforced on all your APIs and services. Every API needs to be versioned and call a specific service version (or range), and this same approach should be applied to every service. To achieve this, your API management solution must provide a flexible way to express dependencies in API definitions. Furthermore, it should check for dependencies at the deployment phase through intelligent linters to avoid publishing a broken API dependency chain.
These capabilities are uncommon in API management products, so you must choose wisely.
→ Enforce dependency checks at deployment.
Wrap Up
You dedicated most of your career to building DonutGPT’s infrastructure, solving countless challenges during this adventure. The outcome has been quite rewarding: DonutGPT disrupted the donut market thanks to its state-of-the-art AI technology, producing breathtaking donut recipes.
You are proud to be part of this success story; however, while accelerating, the company now faces more complex problems. The biggest problem, by far, is the industrialization of DonutGPT’s APIs consumed by customers and resellers. During this journey, you tried multiple solutions, started over, and made some great decisions… and some debatable ones. DonutGPT messed up a few donut orders while exploring the API world.
Now that you can stand back and see the whole project, you realize that you have hit what you consider today to be anti-patterns. Of course, you learned a lot during this process, and you started thinking it would be a great idea to give that knowledge back to the community through a detailed blog post, for example.
Of course, this story, the character, and the company are fictitious, even though AI-generated donut recipes might be the next big thing. However, these anti-patterns are very real and have been observed repeatedly during our multiple conversations at Traefik Labs with our customers, prospects, and community members.
While planning your API journey, you should consider these five principles to maximize your return and minimize your effort:
Design your API platform with a strong separation of concerns. Avoid delegating business logic to the platform.
Do not set the bar too high or too fast. Proceed step by step. Start with more straightforward concepts like ingresses and progressively move to more advanced API use cases once you understand them better.
While industrializing your processes, tolerating exceptions will defeat the purpose, and you won’t gain all the expected benefits of a fully automated platform.
Versioning becomes a critical challenge in the long run. Starting your API journey with a strong and consistent versioning strategy across all your APIs will make your platform more scalable, reliable, and predictable.
Within complex infrastructures with many moving parts, controlling and certifying runtime dependencies for all components is crucial to achieving a high level of trust and stability for your platform.
Of course, this list is not exhaustive, but it covers the most common practices. All that said, these recommendations should not prevent you from drifting away and trying different processes. Innovation is built on top of others’ feedback, but still requires creativity.
Platform engineering involves creating a supportive, scalable and efficient infrastructure that allows developers to focus on delivering high-quality software quickly. Many of us have been doing this approach for years, just without a proper name tied to it.
To get platform engineering right, many have turned to the concept of platforms as products (PaaP), where you put the emphasis on the user experience of the developers themselves and view your internal developers as customers. This implies platforms should have a clear value proposition, a roadmap and dedicated resources so that our internal developers have all the resources we would arm our external customers with if preparing them to onboard into a new product.
However, we can’t discuss the popular trend of treating PaaP without discussing what lies at the heart of this conversation. The PaaP approach is particularly pivotal in the realm of internal developer platforms (IDPs), which are central to the platform engineering craze because you can’t get your external platform right if your internal one is a mess. Traditional approaches often overlook the necessity of aligning the platform’s capabilities with developers’ needs, leading to poor adoption and suboptimal outcomes.
This is where internal developer platforms come into play, serving as the backbone of this engineering paradigm. These platforms are not just about providing tools and services; they are about crafting an experience that empowers developers to perform their best work. When platforms are designed with a deep understanding of what developers truly need, they can significantly enhance productivity and satisfaction.
IDPs are usually referred to as developer-focused infrastructure platforms (not to be confused with a developer control plane) and were made popular by the well-known “Team Topologies” book (they’re something we’ve prioritized for a long time here at Ambassador). “Team Topologies” focuses on structuring business and technology teams for peak efficiency, and a big focus is highlighting the need for platform teams to offer platforms as an internal product to enable and accelerate other teams.
The benefit of internal platforms is that they enable teams to spend more time on delivering business value, provide guardrails for security and compliance, standardize across teams and create an ease of deployment. Here’s why IDPs are critical to build that solid foundation for your IDP and perfect your platform strategy as a whole:
worldwide so they can code, ship and run apps fast
Why Internal Developer Platforms Are Critical
Enhanced Developer Experience (DX)
Internal developer platforms focus on improving the overall developer experience, making it easier for developers to access the tools and resources they need. Your developers should not be dreading their experience; instead, they should be able to focus on the things that matter most: good development.
The more you focus on making your internal platform friction-free, it will lead to increased efficiency and creativity as developers are able to focus more on solving business problems rather than grappling with infrastructural complexities. With easier access to tools and fewer operational hurdles, developers can experiment and innovate more freely. This environment encourages the exploration of new technologies and approaches, which can lead to breakthroughs in product development.
Friction-free IDPs include well-documented processes, standardized tools and removing manual work where possible (automation is your friend). If you’ve built your IDP to meet these requirements, then your devs will be happier and more productive.
Streamlined Operations and Resource Management
Speaking of standardization — by standardizing development environments, internal platforms reduce variability and streamline operations across the development life cycle. This not only speeds up the development process but also reduces the likelihood of errors, leading to more stable releases.
Having components and tools centralized in an internal developer platform streamlines the foundation for developer self-service, success and responsibility. A developer platform empowers both developers and platform engineers to focus on and excel in their core business areas, and enable faster development cycles and the ability to ship software with speed and safety.
A strong IDP allows organizations to optimize resource usage, ensuring that developers have access to necessary resources without overprovisioning. This can lead to cost savings and more efficient use of infrastructure.
And as a bonus, a comprehensive IDP helps you not just attract new talent but retain it as well. In a competitive tech landscape, devs are looking for environments where they can increase their skills and work on exciting projects that don’t compromise their intelligence or threaten their ability to innovate freely. Well-designed internal developer platforms can be a key differentiator in whether future devs will want to work on your team.
Avoiding Common Anti-Patterns That Undermine Your API Strategy
A recent example made this recommendation very clear. Anti-patterns that can undermine API management are largely the result of a lack of a cohesive strategy and plan, and biting off more than a team can chew. This is where we see the opportunity for a platform approach to API development.
IDPs help you craft your API platform with a clear division of responsibilities, ensuring that business logic remains separate from the platform itself.
“I’d argue that anyone who develops software these days has a platform. Accidental platforms, in many cases, are more difficult to manage. Try to take an active role in managing your platform to avoid issues later on,” said Erik Wilde, an industry influencer and recent guest on the “Living on the Edge” podcast.
Therefore, to truly make internal developer platforms a centerpiece of platform engineering and get it right the first time, organizations need to adopt a few strategic practices:
Understand and anticipate developer needs: Continuous feedback mechanisms should be implemented to ensure the platform evolves in line with developer requirements. Any tool you select should be selected with your developers’ needs in mind, applying a holistic lens throughout every piece of your platform. Recognizing that with complex environments with numerous components, managing and certifying runtime dependencies is essential to maintaining high levels of trust with your developers and the stability in your platform.
Be aware that versioning is a significant challenge over time. Implementing a consistent versioning strategy from the start for all your APIs will enhance your platform’s scalability, reliability and predictability.
Invest in scalability: As the organization grows, the platform should be able to scale seamlessly to accommodate more developers and increase workload without performance dips. Ensure the tools you’re building your platform on come with the proper flexibility, room for integrations and composability to expand with your future anticipated growth.
Ensure robust security and compliance: The platform should incorporate strong security measures and compliance controls to protect sensitive data and meet regulatory requirements. Standardization and proper governance can help promote the security of your IDP, but ensure the proper code reviews, protections and protections from security risks are all in place before you socialize your IDP.
Promote internal adoption: Through internal promotion and demonstrating clear value propositions, you can encourage widespread adoption of the platform. Involve your own devs early and often in the process, and consider involving other relevant stakeholders as well (think product managers, business leadership, someone from your operations team, etc.). And remember: While it might be obvious to developers and their managers that an IDP could increase developer productivity and focus, it’s not always obvious to other stakeholders. Chances are you’re going to have to prove that your IDP can unlock developer effectiveness and efficiency by building a business case.
There Is No Platform Engineering Without IDPs
In the end, internal developer platforms (IDPs) are not merely a component of platform engineering; they are its core. As platform engineering evolves, placing IDPs at the heart of this transformation is essential for organizations aspiring to lead in the digital age. With the ongoing migration to the cloud and the customization of platforms atop this infrastructure, a deep understanding of IDPs and their pivotal role in platform engineering is becoming increasingly crucial.
The ECMAScript standard for JavaScript continues to add new language features in a deliberate way. This year there’s a mix of APIs that standardize common patterns that developers have been writing by hand or importing from third-party libraries — including some aimed specifically at library authors — plus improvements in string handling, regular expressions, multithreading and WebAssembly interoperability.
Meanwhile, the TC39 committee that assesses proposals is also making progress on some of the much larger proposals, like the long-awaited Temporal and Decorators that may be ready for ECMAScript 2025, Ecma vice president Daniel Ehrenberg told The New Stack.
“Looking at what we’ve done over the past year, ECMAScript 2024 is a little similar to ECMAScript 2023 in that it sees smaller features; but meanwhile, we’re building very strongly towards these big features.” Many of those only need “the last finishing touches.”
“You need to access the WebAssembly heap reasonably efficiently and frequently from the JavaScript side, because in real applications you will not have communication between the two.” – Daniel Ehrenberg, Ecma vice president
In fact, since the completed feature proposals for ECMAScript 2024 were signed off in March of this year, ready for approval of the standard in July, at least one important proposal — Set Methods — has already reached stage four, ready for 2025.
Making Developers Happier With Promises
Although promises are a powerful JavaScript feature introduced in ECMAScript 2015, the pattern the promise constructor uses isn’t common elsewhere in JavaScript, and turned out not to be the way developers want to write code, Ehrenberg explained. “It takes some mental bandwidth to use these weird idioms.”
The hope was that over time on the web platform, enough APIs would natively return promises instead of callbacks that developers wouldn’t often need to use the promise constructor. However, existing APIs haven’t changed to be more ergonomic.
“It comes up at least once in every project. Almost every project was writing this same little helper so it being in the language is one of those really nice developer happiness APIs.” – Ashley Claymore, Bloomberg software engineer
Instead, developers are left with a cumbersome workaround that many libraries, frameworks and other tools — from React to TypeScript — have implemented different versions of: it’s in jQuery as the deferred function. “People have this boilerplate pattern that they have to write over and over again, where they call the promise constructor, they get the resolve and reject callbacks, they write those to a variable, and then they inevitably do something else [with them]. It’s just an annoying piece of code to write,” said Ehrenberg.
Libraries that implemented promises before ECMAScript 2015 typically covered this, but the feature didn’t make it into the language; Chrome briefly supported and then removed a similar option. But developers still need this often enough that the Promise.withResolvers proposal to add a static method made it through the entire TC39 process in the twelve months between ECMAScript 2023 being finalized and the cutoff date for this year’s update to the language — an achievement so unusual that TC-39 co-chair Rob Palmer referred to it as a speedrun.
“Previously, when you created a promise, the ways that you resolve it and you give it its final state were APIs only accessible inside the function that you built the promise with,” Ehrenberg continued. “Promise.withResolvers gives you a way to create a promise and it gives you direct access to those resolution functions.”
Other functions in your code might depend on whether a promise is resolved or rejected, or you might want to pass the function to something else that can resolve the promise for you, reflecting the complex ways promises are used for orchestration in modern JavaScript, Ashley Claymore (a Bloomberg software engineer who has worked on multiple TC39 proposals) suggested.
“The classical way of creating a promise works well when it’s a small task that’s asynchronous; taking something that was purely callback based or something that was promise-like, and then wrapping it up so it was actually a promise,” Claymore said. “In any code where I start doing lots of requests and need to line them up with IDs from elsewhere, so I’m putting promises or resolve functions inside a map because I’m orchestrating lots of async things that aren’t promise based, you’re always having to do this. I need to pull these things out because I’m sending them to different places.”
“It comes up at least once in every project. Almost every project was writing this same little helper so it being in the language is one of those really nice developer happiness APIs.”
Other improvements to promises are much further down the line; Claymore is involved in a proposal to simplify combining multiple promises without using an array — which involves keeping track of which order all the promises are in. “That works fine for like one, two or three things: after that, it can start getting harder to follow the code,” he said. “What was the fifth thing? You’re counting lines of code to make sure you’ve got the right thing.”
Having an Await dictionary of Promises would let developers name promises: particularly helpful when they cover different areas — like gathering user information, database settings and network details that likely return at very different times. This wouldn’t be a difficult feature to develop: the delay is deciding whether it’s useful enough to be in the language because the TC39 committee wants to avoid adding too many niche features that could confuse new developers.
Keeping Compatibility and Categorizing Data
That’s not a concern for the second major feature in ECMAScript 2024, a new way to categorize objects into categories using Array grouping: something common in other languages (including SQL) that developers frequently import the Lodash userland library for.
You can pass in different items and classify them by some property, like color. “The result is a key value dictionary that is indexed by ‘here’s all your green things, here are your orange things’ and that dictionary can be expressed either as an object or a map”, Palmer explained. Use a map if you want to group keys that aren’t only strings and symbols; to extract multiple data values at the same time (known as destructuring), you need an object.
“As a standards committee we shouldn’t be asking them to incur the cost of risking outages when we already know that something is highly risky.” – Ehrenberg
That’s useful for everything from bucketing performance data about your web site to grouping a list of settled promises by status, a common use with Promise.allSettled, Claymore said. “You give it an array of promises, it will wait for all of them to settle, then you get back an array of objects that says, ‘did this reject or did it resolve?’ They’re in the same order as you started, but it’s quite common to have one bit of code I want to give all the promises that were successful and resolved, and another bit of code I want to give rejected [promises].” For that you can pass the result of Promise.allSettled to groupBy to group by promise status, which groups all the resolved promises and all the rejected promises separately.
Building the new grouping functionality also delivered a useful lesson about web compatibility.
The utilities in Lodash are functionality that developers could write in 5-10 lines of code, Palmer noted. “But when you look at the frequency at which they’re used, they’re so widely used by so many programs that at some point it’s worth taking the top usage ones and then putting them in the platform, so people don’t have to write their own.” A number of them have now ended up as native constructs.
“This functionality being in the language is a really nice convenience for projects that are trying not to have a large set of dependencies while still having access to these really common things,” Claymore agreed. “They’re not the hardest things to write by hand, but it’s no fun rewriting them by hand and they can subtly get them wrong.”
Unusually, the new Map.groupBy and Object.groupBy methods are static methods rather than array methods, the way Lodash functionality has previously been added to JavaScript. That’s because two previous attempts to add this functionality as array methods both clashed (in different ways) with existing code on websites already using the same two names the proposal came up with, including the popular Sugar library.
This problem could recur any time TC39 proposals try to add new prototype methods to arrays or instance methods, Palmer warned. “Whenever you try and think of any reasonable English language verb you might want to add, it seems it triggers web compatibility problems somewhere on the internet.”
Ideally, good coding standards would avoid that, but part of the reason it takes time to add new features to JavaScript is the need to test for exactly these kinds of issues and work around them when they crop up.
“We can say that the best practice for the web is that users should not be polluting the global prototypes: people should not be adding properties to array or prototype [in their code], because it can lead to web compatibility issues. But it doesn’t matter how much we say that; these sites are already up there, and we have a responsibility to not break them.”
Shipping then withdrawing implementations in browsers makes it more expensive to add new features, Ehrenberg added. “As a standards committee, we shouldn’t be asking them to incur the cost of risking outages when we already know that something is highly risky.” That means similar proposals might use static methods more in the future to avoid the issue.
Updating JavaScript for Better Unicode Handling
JavaScript already has a /u flag for regexp that needs to handle Unicode (introduced in ECMAScript 2015), but that turned out to have some oddities and missing features. The new /v flag fixes some of those (like getting different results if you use an upper or lowercase character when matching, even if you specify that you don’t care about the case) and forces developers to escape special characters. It also allows you to do more complex pattern matching and string manipulation using a new unicodeSets mode, which lets you name Unicode sets so that you can refer to the ASCII character set or the emoji character set.
The new options will simplify internationalization and make it easier to support features for diversity. The /u flag already lets you refer to emoji, but only if they were only a single character — excluding emoji that combine multiple characters to get a new emoji or to specify the gender or skin tone of an emoji representing a person, and even some country flags.
It also simplifies operations like sanitizing or verifying inputs, by adding more set operations including intersections and nesting, making complex regular expressions more readable. “It adds subtraction so you could say, for example, ‘all the ASCII characters’, but then subtract the digits zero to nine, and that would match a narrower range than all of the ASCII characters,” Palmer explained. You could remove invisible characters or convert numbers expressed as words into digits.
“It’s easy to make assumptions about Unicode, and it’s such a big topic; the number of people in the world [who] understand these things well enough to not make mistakes is very small.” – Claymore
You can also match against various properties of strings, such as what script they’re written in, so that you can find characters like π and treat them differently from p in another language.
You can’t use the /u flag and the /v flag together and you will probably always want to use /v. Palmer described the choice as “the /v flag enables all the good parts of the/ u flag with new features and improvements, but some of them are backwards incompatible with the /u flag.”
ECMAScript 2025 will add another useful improvement for regexp: being able to use the same names in different branches of a regexp. Currently, if you’re writing a regular expression to match something that can be expressed in multiple ways, like the year in a date that might be /2024 or just /24, you can’t use ‘year’ in both branches of the regular expression, even though only one branch can ever match, so you have to say ‘year1’ and ‘year2’ or ‘shortyear’ and ‘longyear’.
“Now we say that’s no longer an error, and you can have multiple parts of the regular expression given the same name, as long as they are on different branches and as long as only one of them can ever be matched,” Claymore explained.
Another new feature in ECMAScript 2024 improves Unicode handling by ensuring that code is using well-formed Unicode strings.
Strings in JavaScript are technically UTF-16 encoded: in practice, JavaScript (like a number of other languages) doesn’t enforce that those encodings are valid UTF-16 even though that’s important for the URI API and the WebAssembly Component Model, for example. “There are various APIs in the web platform that need well-formed strings and they might throw an error or silently replace the string if they get bad data,” Palmer explained.
Because it’s possible for valid JavaScript code to use strings that are invalid UTF sequences, developers need ways to check for that. The new isWellFormed method checks that a JavaScript string is correctly encoded; if not, the new .toWellFormed method fixes the string by replacing anything that isn’t correctly encoded with the 0xFFFD replacement character �.
While experienced Unicode developers could already write checks for this, “It’s very easy to get wrong,” Claymore noted. “It’s easy to make assumptions about Unicode, and it’s such a big topic; the number of people in the world that actually properly understand these things well enough to not make mistakes is very small. This encourages people to fall into the pit of success rather than try and do these things by hand and make mistakes because of not knowing all the edge cases.”
Having it in the language itself might even prove more efficient, Palmer suggested. “Potentially, one of the advantages of delegating this to the JavaScript engine is that it might be able to find faster ways to do this check. You could imagine, for example, it might just cache a single bit of information with every string to say ’I’ve already checked this, this string is not good’ so that every time you pass it somewhere that needs a good string, it doesn’t need to walk every character to check it again, but just look at that one bit.”
Adding Locks With Async Code
“On the main thread, where you’re providing interactivity to the user, it’s one of the rules of the web: thou shalt not halt the main thread!” – Rob Palmer, TC-39 co-chair
JavaScript is technically a single-threaded language that supports multithreading and asynchronous code. That’s because as well as having web workers and service workers that are isolated from the main thread that provides the user interface, it’s the nature of the web that quite often you’re waiting for something from the network or the operating system, so the main thread can run other code.
The tools in JavaScript for managing this continue to get more powerful with a new option in ECMAScript 2024, Atomics.waitAsync.
“If you want to do multithreading in JavaScript, we have web workers, you can spin up another thread, and the model that was originally based on is message passing, which is nice and safe,” Palmer explained. “But for people [who] want to go faster, where that becomes a bottleneck, shared memory is the more raw, lower-level way of having these threads cooperate on shared data, and SharedArrayBuffer was introduced long ago to permit this memory sharing. And when you’ve got a multithreaded system with shared memory, you need locks to make sure that you got orderly operations.”
“When you wait, you lock up the thread, it can’t make any progress. And that’s fine on a worker thread. On the main thread, where you’re providing interactivity to the user, it’s one of the rules of the web: thou shalt not halt the main thread!”
Async avoids blocking the main thread because it can move on to any other tasks that are ready to go, like loading data that has come in from the network, and the Atomics.wait API offers event-based waiting when you’re not on the main thread. But sometimes you do want the main thread to wait for something.
“Even if you’re not on the main thread, you shouldn’t be blocking most of the time,” Ehrenberg warned, while noting that “it was important for game engines to be allowed to block when they’re not on the main thread, to be able to recreate what they could do in C++ code bases.”
Developers who need this have created workarounds for this, again using message passing, but this had some overheads and slowed things down. Atomics.waitAsync can be used on the main thread and provides a first-class way of waiting on a lock. “The key thing is that it doesn’t stall the main thread,” Palmer said.
“If you call it and the lock is not ready, it will instead give you a backup promise so [that] you can use regular async.await and treat it just like any other promise. This solves how to have high-performance access operations on locks.”
Another proposal still in development takes a slightly different approach to waiting on the main thread and would be useful for making multithreaded applications written in Emscripten more efficient. Atomics.pause promises ‘microwaits’ that can be called from the main thread or worker threads. “It does block, but it’s limited in how long it can block for,” Claymore told us.
Most JavaScript developers won’t use either of these options directly, Palmer pointed out: “It’s very hard to write threaded code.” But mutex libraries would likely rely on it, as might tools for compiling to WebAssembly.
“We can all benefit from this, even if we’re not using it directly.”
Easier WebAssembly Integration
Another proposal for adding a JavaScript API for features previously handled in DOM APIs or available to WebAssembly bytecode, but not JavaScript, is resizable array buffers.
WebAssembly and JavaScript programs need to share memory. “You need to access the WebAssembly heap reasonably efficiently and frequently from the JavaScript side, because in real applications you will not have communication between the two sides; they’re largely sharing their information via the heap,” Ehrenberg explained.
“If you’ve got a WebAssembly toolchain like Emscripten, it means it can do this without creating wrapper objects.” – Palmer
WebAssembly memory can grow if required: but if it does and you want to access it from JavaScript, that means detaching the ArrayBuffer you’re using for handling binary data in memory and building a new TypedArray over the underlying ArrayBuffer next time you need to access the heap. That’s extra work that fragments the memory space on 32-bit systems.
Now you can create a new type of array buffer that’s resizable, so it can grow or shrink without needing to be detached.
“If you’ve got a WebAssembly toolchain like Emscripten, it means it can do this without creating wrapper objects, which just add inefficiencies,” Palmer added. Again, while few JavaScript developers will use this directly, libraries will likely use resizable arrays for efficiency and no longer need to work around a missing part of the language to do it — making them smaller and faster to load by reducing the amount of code that needs to be downloaded.
Developers have to explicitly choose this, because array buffers and typed arrays are the most common way hackers try to attack browsers, and making the existing ArrayBuffer resizable would mean changing a lot of code that’s been extensively tested and hardened, possibly creating bugs and vulnerabilities.
“That detach operation was initially created to enable transfer to and from workers,” Ehrenberg explained. “When you send an ArrayBuffer via a POST message to transfer it to another worker, the ownership transfers and all the typed arrays that are closing over that ArrayBuffer become detached.” A companion proposal lets developers transfer the ownership of array buffers so they can’t be tampered with.
“If you pass it into a function, the receiver can use this transfer function to acquire ownership, so anyone who used to have a handle to it no longer has it,” Palmer explained. “That’s good for integrity.”
As well as being part of ECMAScript 2024, resizable array buffers have been integrated into the WebAssembly JS API; Ehrenberg called this out as an example of collaboration between different communities in the web ecosystem that’s working well.
“These are efforts that span multiple different standards committees and require explicit cooperation among them. That can be complicated because you have to bring a lot of people in the loop, but ultimately, I think it leads to [a] good design process. You get a lot of vetting.”
Generative AI is booming as industries and innovators look for ways to transform digital experiences. From AI chatbots to language translation tools, people are interacting with a common set of AI/ML models, known as language models in everyday scenarios. As a result, new language models have developed rapidly in size, performance and use cases in recent years.
As an application developer, you may want to integrate a high-performance model by simply making a REST call and pointing your app to an inferencing endpoint for options like Falcon, Mistral, Phi and other models. Just like that, you’ve unlocked the doors to the AI kingdom and all kinds of intelligent applications.
Open source language models are a cost-effective way to experiment with AI, and Kubernetes has emerged as the open source platform best suited for scaling and automating AI/ML applications without compromising the security of user and company data.
“Let’s make Kubernetes the engine of AI transformation,” said Jorge Palma, Microsoft principal product manager lead. He gave the keynote at KubeCon Europe 2024, where AI use cases were discussed everywhere. Palma talked about the number of developers he’s met who are deploying models locally in their own infrastructure, putting them in containers and using Kubernetes clusters to host them.
“Container images are a great format for models. They’re easy to distribute,” Palma told KubeCon. “Then you can deploy them to Kubernetes and leverage all the nice primitives and abstractions that it gives you — for example, managing that heterogeneous infrastructure, and at scale.”
Containers also help you avoid the annoying “but it runs fine on my machine” issue. They’re portable, so your models run consistently across environments. They simplify version control to better maintain iterations of your model as you fine-tune for performance improvements. Containers provide resource isolation, so you can run different AI projects without mixing up components. And, of course, running containers in Kubernetes clusters makes it easy to scale out — a crucial factor when working with large models.
“If you aren’t going to use Kubernetes, what are you going to do?” asked Ishaan Sehgal, a Microsoft software engineer. He is a contributor to the Kubernetes AI Toolchain Operator (KAITO) project and has helped develop its major components to simplify AI deployment on a given cluster. KAITO is a Kubernetes operator and open source project developed at Microsoft that runs in your cluster and automates the deployment of large AI models.
As Sehgal pointed out, Kubernetes gives you the scale and resiliency you need when running AI workloads. Otherwise, if a virtual machine (VM) fails or your inferencing endpoint goes down, you must attach another node and set everything up again. “The resiliency aspect, the data management — Kubernetes is great for running AI workloads, for those reasons,” he said.
Kubernetes Makes It Easier, KAITO Takes It Further
Kubernetes makes it easier to scale out AI models, but it’s not exactly easy. In my article “Bring your AI/ML workloads to Kubernetes and leverage KAITO,” I highlight some of the hurdles that developers face with this process. For example, just getting started is complicated. Without prior experience, you might need several weeks to correctly set up your environment. Downloading and storing the large model weights, upwards of 200 GB in size, is just the beginning. There are storage and loading time requirements for model files. Then you need to efficiently containerize your models and host them — choosing the right GPU size for your model while keeping costs in mind. And there are troubleshooting pesky quota limits on compute hardware.
Using KAITO, a workflow that previously could span weeks now takes only minutes. This tool streamlines the tedious details of deploying, scaling, and managing AI workloads on Kubernetes, so you can focus on other aspects of the ML life cycle. You can choose from a range of popular open source models or onboard your custom option, and KAITO tunes the deployment parameters and automatically provisions GPU nodes for you. Today, KAITO supports five model families and over 10 containerized models, ranging from small to large language models.
For an ML engineer like Sehgal, KAITO overcomes the hassle of managing different tools, add-ons and versions. You get a simple, declarative interface “that encapsulates all the requirements you need for running your inferencing model. Everything gets set up,” he explained.
How KAITO Works
Using KAITO is a two-step process. First, install KAITO on your cluster, and then select a preset that encapsulates all the requirements needed for inference with your model. Within the associated workspace custom resource definition (CRD), a minimum GPU size is recommended so you don’t have to search for the ideal hardware. You can always customize the CRD to your needs. After deploying the workspace, KAITO uses the node provisioner controller to automate the rest.
“KAITO is basically going to provision GPU nodes and add them to your cluster on your behalf,” explained Microsoft senior cloud evangelist Paul Yu. “As a user, I just have to deploy my workspace into the AKS cluster, and that creates the additional CR.”
As shown in the following KAITO architecture, the workspace invokes a provisioner to create and configure the right-sized infrastructure for you, and it even distributes your workload across smaller GPU nodes to reduce costs. The project uses open source Karpenter APIs for the VM configuration based on your requested size, installing the right drivers and device plug-ins for Kubernetes.
For applications with compliance requirements, KAITO provides granular control over data security and privacy. You can ensure that models are ring-fenced within your organization’s network and that your data never leaves the Kubernetes cluster.
Currently, you can use KAITO to provision GPUs on Azure, but the project is evolving quickly. The roadmap includes support for other managed Kubernetes providers. When you use a managed Kubernetes service, you can interact with other services from that cloud platform more easily to add capabilities to your workflow or applications.
Brendan Burns, co-founder of the Kubernetes open source project, introduced the demo. “What we’re seeing is, as people are using Azure OpenAI Service, they’re building the rest of the application on top of AKS,” he told the audience. “But, of course, just using OpenAI Service isn’t the only thing you might want to use. There are a lot of reasons why you might want to use open source large language models, including situations like data and security compliance, and fine-tuning what you want to do. Maybe there’s just a model out there that’s better suited to your task. But doing this inside of AKS can be tricky so we integrated the Kubernetes AI Toolchain Operator as an open source project.”
Make Your Language Models Smarter with KAITO
Open-source language models are trained on extensive amounts of text from a variety of sources, so the output for domain-specific prompts may not always meet your needs. Take the pet store application, for example. If a customer asks the integrated pre-trained model for dog food recommendations, it might give different pricing options across a few popular dog breeds. This is informative but not necessarily useful as the customer shops. After fine-tuning the model on historical data from the pet store, the recommendations can instead be tailored to well-reviewed, affordable options available in the store.
As a step in your ML lifecycle, fine-tuning helps customize open source models to your own data and use cases. The latest release of KAITO, v0.3.0, supports fine-tuning, and inference with adapters and a broader range of models. You can simply define your tuning method and data source in a KAITO workspace CR and see your intelligent app become more context-aware while maintaining data security and compliance requirements in your cluster.
To stay up to date on the project roadmap and test these new features, check out KAITO on GitHub.
Three powerful perspectives are colliding on how to control AI:
All AI should be open source for sharing and transparency.
Keep AI closed-source and allow big tech companies to control it.
Establish regulations for the use of AI.
There are a few facts that make this debate tricky. First, if you have a model’s source code, you know absolutely nothing about how the model will behave. Openness in AI requires far more than providing source code. Second, AI comes in many different flavors and can be used to solve a broad range of problems.
From traditional AI for fraud detection and targeted advertising to generative AI for creating chatbots that, on the surface, produce human-like results, pushing us closer and closer to the ultimate (and scary) goal of Artificially Generated Intelligence (AGI). Finally, the ideas listed above for controlling AI all have a proven track record for improving software in general.
Understanding the Different Perspectives
Let’s discuss the different perspectives listed above in more detail.
Perspective #1 — All AI should be open source for sharing and transparency: This comes from a push for transparency with AI. Open source is a proven way to share and improve software. It provides complete transparency when used for conventional software. Open source software has propelled the software industry forward by leaps and bounds.
Perspective #2 — Keep AI closed-source and allow big tech companies to control it: Closed-source, or proprietary software, is the idea that an invention can be kept a secret, away from the competition, to maximize financial gain. To open source idealists, this sounds downright evil; however, it is more of a philosophical choice than one that exists on the spectrum of good and evil. Most software is proprietary, and that is not inherently bad — it is the foundation of a competitive and healthy ecosystem. It is a fundamental right of any innovator who creates something new to choose the closed-source path. The question becomes, if you operate without transparency, what guarantees can there be around responsible AI?
Perspective #3 — Establish regulations for using AI: This comes from lawmakers and elected officials pushing for regulation. The basic idea is that if a public function or technology is so powerful that bad actors or irresponsible management could hurt the general public, a government agency should be appointed to develop controls and enforce those controls. A school of thought suggests that incumbent and current leaders in AI also want regulation, but for reasons that are less pure — they want to freeze the playing field with them in the lead. We will primarily focus on the public good area.
The True Nature of Open Source
Before generative AI burst onto the scene, most software running in data centers was conventional. You can determine precisely what it does if you have the source code for traditional software. An engineer fluent in the appropriate programming language can review the code and determine its logic. You can even modify it and alter its behavior. Open source (or open source code) is another way of saying — I am going to provide everything needed to determine behavior and change behavior. In short, the true nature of open source software is to provide everything you need to understand the software’s behavior and change it.
For a model to be fully open, you need the training data, the source code of the model, the hyperparameters used during training, and, of course, the trained model itself, which is composed of the billions (and soon trillions) of parameters that store the model’s knowledge — also known as parametric memory. Now, some organizations only provide the model, keep everything else to themselves, and claim it is “open source.” This practice is known as “open-washing” and is generally frowned upon by both the open and closed-source communities as disingenuous. I would like to see a new term used for AI models that are partially shared. Maybe “partially open model” or “model from an open washing company.”
There is one final rub when it comes to fully shared models. Let’s say an organization wants to do the right thing and shares everything about a model — the training data, the source code, the hyperparameters, and the trained model. You still can’t determine precisely how it will behave unless you test it extensively. The parametric memory that determines behavior is not human-readable. Again, the industry needs a different term for fully open models. A term that is different from “open source,” which should only be used for non-AI software because the source code of a model does not help determine the behavior of the model. Perhaps “open model.”
Common Arguments
Let’s look at some common arguments that endorse using only one of the previously described perspectives. These are passionate defenders of their perspective, but that passion can cloud judgment.
Argument: Closed AI supporters claim that big tech companies have the means to guard against potential dangers and abuse. Therefore, AI should be kept private and out of the open source community.
Rebuttal: Big tech companies have the means to guard against potential abuse, but that does not mean they will do it judiciously or at all. Furthermore, there are other objectives besides this. Their primary purpose is making money for their shareholders, which will always take precedence.
Argument: Those who think that AI could threaten humanity like to ask, “Would you open source the Manhattan Project?”
Rebuttal: This is an argument for governance. However, it is an unfair and incorrect analogy. The purpose of the Manhattan Project was to build a bomb during wartime by using radioactive materials to produce nuclear fusion. Nuclear fusion is not a general-purpose technology that can be applied to different tasks. You can make a bomb and generate power — that’s it. The ingredients and the results are dangerous to the general public, so all aspects should be regulated. AI is much different. As described above, it comes in varying flavors with varying risks.
Argument: Proponents of open sourcing AI say that open source facilitates the sharing of science, provides transparency, and is a means to prevent a few from monopolizing a powerful technology.
Rebuttal: This is primarily true, but it is not entirely true. Open source does provide sharing. For an AI model, it is only going to provide some transparency. Finally, whether “open models” will prevent a few from monopolizing their power is debatable. To run a model like ChatGPT at scale, you must compute that only a few companies can acquire it.
Needs of the Many Outweigh the Needs of the Few
In “Star Trek II: The Wrath of Khan,” Spock dies from radiation poisoning. Spock realizes that the ship’s main engines must be repaired to facilitate an escape, but the engine room is flooded with lethal radiation. Despite the danger, Spock enters the radiation-filled chamber to make the necessary repairs. He successfully restores the warp drive, allowing the Enterprise to reach a safe distance. Unfortunately, Vulcans are not immune to radiation. His dying words to Captain Kirk explain the logic behind his actions, “The needs of the many outweigh the needs of the few or the one.”
This is perfectly sound logic and will have to be used to control AI. Specific models pose a risk to the general public. For these models, the general public’s needs outweigh innovators’ rights.
Should All AI Be Open Source?
Let’s review the axioms established thus far:
Open Source should remain a choice.
Open models are not as transparent as non-AI software that is open sourced.
Close Source is a right of the innovator.
There is no guarantee that big tech will correctly control their AI.
The needs of the general public must take precedence over all others.
The five bullets above represent everything I tried to make clear about open source, closed source, and regulations. If you believe them to be accurate, the answer to the question, “Should All AI be Open Source?” is no because it will not control AI, nor will a closed source. Furthermore, in a fair world, open source and open models should remain a choice, and close source should remain a right.
We can go one step further and talk about the actions the industry can take as a whole to move toward effective control of AI:
Determine the types of models that pose a risk to the general public. Because they control information (chatbots) or dangerous resources (automated cars), models with high risk should be regulated.
Organizations should be encouraged to share their models as fully open models. The open source community will need to step up and either prevent or label models that are only partially shared. The open source community should also put together tests that can be used to rate models.
Closed models should still be allowed if they do not pose a risk to the general public. Big Tech should develop its controls and tests that it funds and shares. This may be a chance for Big Tech to work closely with the open source community to solve a common problem.
To recap, an agent sends the user query (1) along with the available tools (2) to a cloud-based LLM to map the prompt into a set of functions and arguments (3). It then executes the functions to generate appropriate context from a database (4a). If there are no tools involved, it leverages the simple RAG mechanism to perform a semantic search in a vector database (4b). The context gathered from either of the sources is then sent (5) to an edge-based SLM to generate a factually correct response. The response (6) generated by the SLM is sent as the final answer (7) to the user query.
This tutorial focuses on the practical implementation of a federated LM architecture based on the below components:
Start by cloning the Git repository https://github.com/janakiramm/federated-llm.git, which has the scripts, data, and Jupyter Notebooks. This tutorial assumes that you have access to OpenAI and an Nvidia Jetson Orin device. You can also run Ollama on your local workstation and change the IP address in the code.
Step 1: Run Ollama on Jetson Orin
SSH into Jetson Orin and run the commands mentioned in the file, setup_ollama.sh.
Verify that you are able to connect to and access the model by running the below command on your workstation, where you run Jupyter Notebook.
123456789101112131415
curl http://localhost:11434/v1/chat/completions \ -H “Content-Type: application/json” \ -d ‘{ “model”: “phi3:mini”, “messages”: [ { “role”: “system”, “content”: “You are a helpful assistant.” }, { “role”: “user”, “content”: “What is the capital of France?” } ] }’
Replace localhost with the IP address of your Jetson Orin device. If everything goes well, you should be able to get a response from the model.
Congratulations, your edge inference server is now ready!
Step 2: Run MySQL DB and Flask API Server
The next step is to run the API server, which exposes a set of functions that will be mapped to the prompt. To make this simple, I built a Docker Compose file that exposes the REST API endpoint for the MySQL database backend.
Switch to the api folder and run the below command:
1
start_api_server.sh
Check if two containers are running on your workstation with the docker ps command.
If you run the command curl "http://localhost:5000/api/sales/trends?start_date=2023-05-01&end_date=2023-05-30", you should see the response from the API.
Step 3: Index the PDF and Ingest the Embeddings in Chroma DB
With the API in place, it’s time to generate the embeddings for the datasheet PDF and store them in the vector database.
For this, run the Index_Datasheet.ipynb Jupyter Notebook, which is available in the notebooks folder.
A simple search retrieves the phrases that semantically match the query.
Step 4: Run the Federated LM Agent
The Jupyter Notebook, Federated-LM.ipynb, has the complete code to implement the logic. Let’s understand the key sections of the code.
We will import the API client that exposes the tools to the LLM.
We will import the API client that exposes the tools to the LLM.
First, we initialize two LLMs: GPT-4o (Cloud) and Phi3:mini (Edge)
After creating a Python list with the signatures of the tools, we will let GPT-4o map the prompt to appropriate functions and their arguments.
For example, passing the prompt What was the top selling product in Q2 based on revenue? to GPT-4o results in the model responding with the function get_top_selling_products and the corresponding arguments. Notice that a capable model is able to translate Q2 into date range, starting from April 1st to June 30th. This is exactly the power we want to exploit from the cloud-based LLM.
Once we enumerate the tool(s) suggested by GPT-4o, we execute, collect, and aggregate the output to form the context.
If the prompt doesn’t translate to tools, we attempt to use the retriever based on the semantic search from the vector database.
To avoid sending sensitive context to the cloud-based LLM, we leverage the model (edge_llm) at the edge for generation.
Finally, we implement the agent that orchestrates the calls between the cloud-based LLM and the edge-based LLM. It checks if the tools list is empty and then moves to the retriever to generate the context. If both are empty, the agent responds with the phrase “I don’t know.”
Below is the response from the agent based on tools, retriever, and unknown context.
To summarize, we implemented a federated LLM approach where an agent sends the user query along with available tools to a cloud-based LLM, which maps the prompt into functions and arguments. The agent executes these functions to generate context from a database. If no tools are involved, a simple RAG mechanism is used for semantic search in a vector database. The context is then sent to an edge-based SLM to generate a factually correct response, which is provided as the final answer to the user query.
Cybersecurity researchers have uncovered security shortcomings in SAP AI Core cloud-based platform for creating and deploying predictive artificial intelligence (AI) workflows that could be exploited to get hold of access tokens and customer data.
The five vulnerabilities have been collectively dubbed SAPwned by cloud security firm Wiz.
“The vulnerabilities we found could have allowed attackers to access customers’ data and contaminate internal artifacts – spreading to related services and other customers’ environments,” security researcher Hillai Ben-Sasson said in a report shared with The Hacker News.
Following responsible disclosure on January 25, 2024, the weaknesses were addressed by SAP as of May 15, 2024.
In a nutshell, the flaws make it possible to obtain unauthorized access to customers’ private artifacts and credentials to cloud environments like Amazon Web Services (AWS), Microsoft Azure, and SAP HANA Cloud.
They could also be used to modify Docker images on SAP’s internal container registry, SAP’s Docker images on the Google Container Registry, and artifacts hosted on SAP’s internal Artifactory server, resulting in a supply chain attack on SAP AI Core services.
Furthermore, the access could be weaponized to gain cluster administrator privileges on SAP AI Core’s Kubernetes cluster by taking advantage of the fact that the Helm package manager server was exposed to both read and write operations.
“Using this access level, an attacker could directly access other customer’s Pods and steal sensitive data, such as models, datasets, and code,” Ben-Sasson explained. “This access also allows attackers to interfere with customer’s Pods, taint AI data and manipulate models’ inference.”
Wiz said the issues arise due to the platform making it feasible to run malicious AI models and training procedures without adequate isolation and sandboxing mechanisms.
“The recent security flaws in AI service providers like Hugging Face, Replicate, and SAP AI Core highlight significant vulnerabilities in their tenant isolation and segmentation implementations,” Ben-Sasson told The Hacker News. “These platforms allow users to run untrusted AI models and training procedures in shared environments, increasing the risk of malicious users being able to access other users’ data.”
“Unlike veteran cloud providers who have vast experience with tenant-isolation practices and use robust isolation techniques like virtual machines, these newer services often lack this knowledge and rely on containerization, which offers weaker security. This underscores the need to raise awareness of the importance of tenant isolation and to push the AI service industry to harden their environments.”
As a result, a threat actor could create a regular AI application on SAP AI Core, bypass network restrictions, and probe the Kubernetes Pod’s internal network to obtain AWS tokens and access customer code and training datasets by exploiting misconfigurations in AWS Elastic File System (EFS) shares.
“People should be aware that AI models are essentially code. When running AI models on your own infrastructure, you could be exposed to potential supply chain attacks,” Ben-Sasson said.
“Only run trusted models from trusted sources, and properly separate between external models and sensitive infrastructure. When using AI services providers, it’s important to verify their tenant-isolation architecture and ensure they apply best practices.”
The findings come as Netskope revealed that the growing enterprise use of generative AI has prompted organizations to use blocking controls, data loss prevention (DLP) tools, real-time coaching, and other mechanisms to mitigate risk.
“Regulated data (data that organizations have a legal duty to protect) makes up more than a third of the sensitive data being shared with generative AI (genAI) applications — presenting a potential risk to businesses of costly data breaches,” the company said.
They also follow the emergence of a new cybercriminal threat group called NullBulge that has trained its sights on AI- and gaming-focused entities since April 2024 with an aim to steal sensitive data and sell compromised OpenAI API keys in underground forums while claiming to be a hacktivist crew “protecting artists around the world” against AI.
“NullBulge targets the software supply chain by weaponizing code in publicly available repositories on GitHub and Hugging Face, leading victims to import malicious libraries, or through mod packs used by gaming and modeling software,” SentinelOne security researcher Jim Walter said.
“The group uses tools like AsyncRAT and XWorm before delivering LockBit payloads built using the leaked LockBit Black builder. Groups like NullBulge represent the ongoing threat of low-barrier-of-entry ransomware, combined with the evergreen effect of info-stealer infections.”
SolarWinds has addressed a set of critical security flaws impacting its Access Rights Manager (ARM) software that could be exploited to access sensitive information or execute arbitrary code.
Of the 13 vulnerabilities, eight are rated Critical in severity and carry a CVSS score of 9.6 out of 10.0. The remaining five weaknesses have been rated High in severity, with four of them having a CVSS score of 7.6 and one scoring 8.3.
The most severe of the flaws are listed below –
CVE-2024-23472 – SolarWinds ARM Directory Traversal Arbitrary File Deletion and Information Disclosure Vulnerability
CVE-2024-28074 – SolarWinds ARM Internal Deserialization Remote Code Execution Vulnerability
Successful exploitation of the aforementioned vulnerabilities could allow an attacker to read and delete files and execute code with elevated privileges.
The shortcomings have been addressed in version 2024.3 released on July 17, 2024, following responsible disclosure as part of the Trend Micro Zero Day Initiative (ZDI).
The development comes after the U.S. Cybersecurity and Infrastructure Security Agency (CISA) placed a high-severity path traversal flaw in SolarWinds Serv-U Path (CVE-2024-28995, CVSS score: 8.6) to its Known Exploited Vulnerabilities (KEV) catalog following reports of active exploitation in the wild.
The network security company was the victim of a major supply chain attack in 2020 after the update mechanism associated with its Orion network management platform was compromised by Russian APT29 hackers to distribute malicious code to downstream customers as part of a high-profile cyber espionage campaign.
The breach prompted the U.S. Securities and Exchange Commission (SEC) to file a lawsuit against SolarWinds and its chief information security officer (CISO) last October alleging the company failed to disclose adequate material information to investors regarding cybersecurity risks.
However, much of the claims pertaining to the lawsuit were thrown out by the U.S. District Court for the Southern District of New York (SDNY) on July 18, stating “these do not plausibly plead actionable deficiencies in the company’s reporting of the cybersecurity hack” and that they “impermissibly rely on hindsight and speculation.”
The JavaScript downloader malware known as SocGholish (aka FakeUpdates) is being used to deliver a remote access trojan called AsyncRAT as well as a legitimate open-source project called BOINC.
BOINC, short for Berkeley Open Infrastructure Network Computing Client, is an open-source “volunteer computing” platform maintained by the University of California with an aim to carry out “large-scale distributed high-throughput computing” using participating home computers on which the app is installed.
“It’s similar to a cryptocurrency miner in that way (using computer resources to do work), and it’s actually designed to reward users with a specific type of cryptocurrency called Gridcoin, designed for this purpose,” Huntress researchers Matt Anderson, Alden Schmidt, and Greg Linares said in a report published last week.
These malicious installations are designed to connect to an actor-controlled domain (“rosettahome[.]cn” or “rosettahome[.]top”), essentially acting as a command-and-control (C2) server to collect host data, transmit payloads, and push further commands. As of July 15, 10,032 clients are connected to the two domains.
The cybersecurity firm said while it hasn’t observed any follow-on activity or tasks being executed by the infected hosts, it hypothesized that the “host connections could be sold off as initial access vectors to be used by other actors and potentially used to execute ransomware.”
SocGholish attack sequences typically begin when users land on compromised websites, where they are prompted to download a fake browser update that, upon execution, triggers the retrieval of additional payloads to the infiltrated machines.
The JavaScript downloader, in this case, activates two disjointed chains, one that leads to the deployment of a fileless variant of AsyncRAT and the other resulting in the BOINC installation.
The BOINC app, which is renamed as “SecurityHealthService.exe” or “trustedinstaller.exe” to evade detection, sets up persistence using a scheduled task by means of a PowerShell script.
The misuse of BOINC for malicious purposes hasn’t gone unnoticed by the project maintainers, who are currently investigating the problem and finding a way to “defeat this malware.” Evidence of the abuse dates back to at least June 26, 2024.
“The motivation and intent of the threat actor by loading this software onto infected hosts isn’t clear at this point,” the researchers said.
“Infected clients actively connecting to malicious BOINC servers present a fairly high risk, as there’s potential for a motivated threat actor to misuse this connection and execute any number of malicious commands or software on the host to further escalate privileges or move laterally through a network and compromise an entire domain.”
The development comes as Check Point said it’s been tracking the use of compiled V8 JavaScript by malware authors to sidestep static detections and conceal remote access trojans, stealers, loaders, cryptocurrency miners, wipers, and ransomware.
“In the ongoing battle between security experts and threat actors, malware developers keep coming up with new tricks to hide their attacks,” security researcher Moshe Marelus said. “It’s not surprising that they’ve started using V8, as this technology is commonly used to create software as it is very widespread and extremely hard to analyze.”
Organizations in Taiwan and a U.S. non-governmental organization (NGO) based in China have been targeted by a Beijing-affiliated state-sponsored hacking group called Daggerfly using an upgraded set of malware tools.
The campaign is a sign that the group “also engages in internal espionage,” Symantec’s Threat Hunter Team, part of Broadcom, said in a new report published today. “In the attack on this organization, the attackers exploited a vulnerability in an Apache HTTP server to deliver their MgBot malware.”
Daggerfly, also known by the names Bronze Highland and Evasive Panda, was previously observed using the MgBot modular malware framework in connection with an intelligence-gathering mission aimed at telecom service providers in Africa. It’s known to be operational since 2012.
“Daggerfly appears to be capable of responding to exposure by quickly updating its toolset to continue its espionage activities with minimal disruption,” the company noted.
The latest set of attacks are characterized by the use of a new malware family based on MgBot as well as an improved version of a known Apple macOS malware called MACMA, which was first exposed by Google’s Threat Analysis Group (TAG) in November 2021 as distributed via watering hole attacks targeting internet users in Hong Kong by abusing security flaws in the Safari browser.
The development marks the first time the malware strain, which is capable of harvesting sensitive information and executing arbitrary commands, has been explicitly linked to a particular hacking group.
“The actors behind macOS.MACMA at least were reusing code from ELF/Android developers and possibly could have also been targeting Android phones with malware as well,” SentinelOne noted in a subsequent analysis at the time.
MACMA’s connections to Daggerly also stem from source code overlaps between the malware and Mgbot, and the fact that it connects to a command-and-control (C2) server (103.243.212[.]98) that has also been used by a MgBot dropper.
Another new malware in its arsenal is Nightdoor (aka NetMM and Suzafk), an implant that uses Google Drive API for C2 and has been utilized in watering hole attacks aimed at Tibetan users since at least September 2023. Details of the activity were first documented by ESET earlier this March.
“The group can create versions of its tools targeting most major operating system platform,” Symantec said, adding it has “seen evidence of the ability to trojanize Android APKs, SMS interception tools, DNS request interception tools, and even malware families targeting Solaris OS.”
The development comes as China’s National Computer Virus Emergency Response Center (CVERC) claimed Volt Typhoon – which has been attributed by the Five Eyes nations as a China-nexus espionage group – to be an invention of the U.S. intelligence agencies, describing it as a misinformation campaign.
“Although its main targets are U.S. congress and American people, it also attempt[s] to defame China, sow discords [sic] between China and other countries, contain China’s development, and rob Chinese companies,” the CVERC asserted in a recent report.
The U.S. Cybersecurity and Infrastructure Security Agency (CISA) has added two security flaws to its Known Exploited Vulnerabilities (KEV) catalog, based on evidence of active exploitation.
The vulnerabilities are listed below –
CVE-2012-4792 (CVSS score: 9.3) – Microsoft Internet Explorer Use-After-Free Vulnerability
CVE-2024-39891 (CVSS score: 5.3) – Twilio Authy Information Disclosure Vulnerability
CVE-2012-4792 is a decade-old use-after-free vulnerability in Internet Explorer that could allow a remote attacker to execute arbitrary code via a specially crafted site.
It’s currently not clear if the flaw has been subjected to renewed exploitation attempts, although it was abused as part of watering hole attacks targeting the Council on Foreign Relations (CFR) and Capstone Turbine Corporation websites back in December 2012.
On the other hand, CVE-2024-39891 refers to an information disclosure bug in an unauthenticated endpoint that could be exploited to “accept a request containing a phone number and respond with information about whether the phone number was registered with Authy.”
Earlier this month, Twilio said it resolved the issue in versions 25.1.0 (Android) and 26.1.0 (iOS) after unidentified threat actors took advantage of the shortcoming to identify data associated with Authy accounts.
“These types of vulnerabilities are frequent attack vectors for malicious cyber actors and pose significant risks to the federal enterprise,” CISA said in an advisory.
Federal Civilian Executive Branch (FCEB) agencies are required to remediate the identified vulnerabilities by August 13, 2024, to protect their networks against active threats.
A now-patched security flaw in the Microsoft Defender SmartScreen has been exploited as part of a new campaign designed to deliver information stealers such as ACR Stealer, Lumma, and Meduza.
Fortinet FortiGuard Labs said it detected the stealer campaign targeting Spain, Thailand, and the U.S. using booby-trapped files that exploit CVE-2024-21412 (CVSS score: 8.1).
The high-severity vulnerability allows an attacker to sidestep SmartScreen protection and drop malicious payloads. Microsoft addressed this issue as part of its monthly security updates released in February 2024.
“Initially, attackers lure victims into clicking a crafted link to a URL file designed to download an LNK file,” security researcher Cara Lin said. “The LNK file then downloads an executable file containing an [HTML Application] script.”
The HTA file serves as a conduit to decode and decrypt PowerShell code responsible for fetching a decoy PDF file and a shellcode injector that, in turn, either leads to the deployment of Meduza Stealer or Hijack Loader, which subsequently launches ACR Stealer or Lumma.
ACR Stealer, assessed to be an evolved version of the GrMsk Stealer, was advertised in late March 2024 by a threat actor named SheldIO on the Russian-language underground forum RAMP.
“This ACR stealer hides its [command-and-control] with a dead drop resolver (DDR) technique on the Steam community website,” Lin said, calling out its ability to siphon information from web browsers, crypto wallets, messaging apps, FTP clients, email clients, VPN services, and password managers.
It’s worth noting that recent Lumma Stealer attacks have also been observed utilizing the same technique, making it easier for the adversaries to change the C2 domains at any time and render the infrastructure more resilient, according to the AhnLab Security Intelligence Center (ASEC).
The disclosure comes as CrowdStrike has revealed that threat actors are leveraging last week’s outage to distribute a previously undocumented information stealer called Daolpu, making it the latest example of the ongoing fallout stemming from the faulty update that has crippled millions of Windows devices.
The attack involves the use of a macro-laced Microsoft Word document that masquerades as a Microsoft recovery manual listing legitimate instructions issued by the Windows maker to resolve the issue, leveraging it as a decoy to activate the infection process.
The DOCM file, when opened, runs the macro to retrieve a second-stage DLL file from a remote that’s decoded to launch Daolpu, a stealer malware equipped to harvest credentials and cookies from Google Chrome, Microsoft Edge, Mozilla Firefox, and other Chromium-based browsers.
It also follows the emergence of new stealer malware families such as Braodo and DeerStealer, even as cyber criminals are exploiting malvertising techniques promoting legitimate software such as Microsoft Teams to deploy Atomic Stealer.
“As cyber criminals ramp up their distribution campaigns, it becomes more dangerous to download applications via search engines,” Malwarebytes researcher Jérôme Segura said. “Users have to navigate between malvertising (sponsored results) and SEO poisoning (compromised websites).”
The Internet Systems Consortium (ISC) has released patches to address multiple security vulnerabilities in the Berkeley Internet Name Domain (BIND) 9 Domain Name System (DNS) software suite that could be exploited to trigger a denial-of-service (DoS) condition.
“A cyber threat actor could exploit one of these vulnerabilities to cause a denial-of-service condition,” the U.S. Cybersecurity and Infrastructure Security Agency (CISA) said in an advisory.
The list of four vulnerabilities is listed below –
CVE-2024-4076 (CVSS score: 7.5) – Due to a logic error, lookups that triggered serving stale data and required lookups in local authoritative zone data could have resulted in an assertion failure
CVE-2024-1975 (CVSS score: 7.5) – Validating DNS messages signed using the SIG(0) protocol could cause excessive CPU load, leading to a denial-of-service condition.
CVE-2024-1737 (CVSS score: 7.5) – It is possible to craft excessively large numbers of resource record types for a given owner name, which has the effect of slowing down database processing
CVE-2024-0760 (CVSS score: 7.5) – A malicious DNS client that sent many queries over TCP but never read the responses could cause a server to respond slowly or not at all for other clients
Successful exploitation of the aforementioned bugs could cause a named instance to terminate unexpectedly, deplete available CPU resources, slow down query processing by a factor of 100, and render the server unresponsive.
The flaws have been addressed in BIND 9 versions 9.18.28, 9.20.0, and 9.18.28-S1 released earlier this month. There is no evidence that any of the shortcomings have been exploited in the wild.
The disclosure comes months after the ISC addressed another flaw in BIND 9 called KeyTrap (CVE-2023-50387, CVSS score: 7.5) that could be abused to exhaust CPU resources and stall DNS resolvers, resulting in a denial-of-service (DoS).
Docker is warning of a critical flaw impacting certain versions of Docker Engine that could allow an attacker to sidestep authorization plugins (AuthZ) under specific circumstances.
Tracked as CVE-2024-41110, the bypass and privilege escalation vulnerability carries a CVSS score of 10.0, indicating maximum severity.
“An attacker could exploit a bypass using an API request with Content-Length set to 0, causing the Docker daemon to forward the request without the body to the AuthZ plugin, which might approve the request incorrectly,” the Moby Project maintainers said in an advisory.
Docker said the issue is a regression in that the issue was originally discovered in 2018 and addressed in Docker Engine v18.09.1 in January 2019, but never got carried over to subsequent versions (19.03 and later).
The issue has been resolved in versions 23.0.14 and 27.1.0 as of July 23, 2024, after the problem was identified in April 2024. The following versions of Docker Engine are impacted assuming AuthZ is used to make access control decisions –
<= v19.03.15
<= v20.10.27
<= v23.0.14
<= v24.0.9
<= v25.0.5
<= v26.0.2
<= v26.1.4
<= v27.0.3, and
<= v27.1.0
“Users of Docker Engine v19.03.x and later versions who do not rely on authorization plugins to make access control decisions and users of all versions of Mirantis Container Runtime are not vulnerable,” Docker’s Gabriela Georgieva said.
“Users of Docker commercial products and internal infrastructure who do not rely on AuthZ plugins are unaffected.”
It also affects Docker Desktop up to versions 4.32.0, although the company said the likelihood of exploitation is limited and it requires access to the Docker API, necessitating that an attacker already has local access to the host. A fix is expected to be included in a forthcoming release (version 4.33).
“Default Docker Desktop configuration does not include AuthZ plugins,” Georgieva noted. “Privilege escalation is limited to the Docker Desktop [virtual machine], not the underlying host.”
Although Docker makes no mention of CVE-2024-41110 being exploited in the wild, it’s essential that users apply their installations to the latest version to mitigate potential threats.
Earlier this year, Docker moved to patch a set of flaws dubbed Leaky Vessels that could enable an attacker to gain unauthorized access to the host filesystem and break out of the container.
“As cloud services rise in popularity, so does the use of containers, which have become an integrated part of cloud infrastructure,” Palo Alto Networks Unit 42 said in a report published last week. “Although containers provide many advantages, they are also susceptible to attack techniques like container escapes.”
“Sharing the same kernel and often lacking complete isolation from the host’s user-mode, containers are susceptible to various techniques employed by attackers seeking to escape the confines of a container environment.”
Cybersecurity researchers have disclosed a privilege escalation vulnerability impacting Google Cloud Platform’s Cloud Functions service that an attacker could exploit to access other services and sensitive data in an unauthorized manner.
Tenable has given the vulnerability the name ConfusedFunction.
“An attacker could escalate their privileges to the Default Cloud Build Service Account and access numerous services such as Cloud Build, storage (including the source code of other functions), artifact registry and container registry,” the exposure management company said in a statement.
“This access allows for lateral movement and privilege escalation in a victim’s project, to access unauthorized data and even update or delete it.”
Cloud Functions refers to a serverless execution environment that allows developers to create single-purpose functions that are triggered in response to specific Cloud events without the need to manage a server or update frameworks.
The problem discovered by Tenable has to do with the fact that a Cloud Build service account is created in the background and linked to a Cloud Build instance by default when a Cloud Function is created or updated.
This service account opens the door for potential malicious activity owing to its excessive permissions, thereby permitting an attacker with access to create or update a Cloud Function to leverage this loophole and escalate their privileges to the service account.
This permission could then be abused to access other Google Cloud services that are also created in tandem with the Cloud Function, including Cloud Storage, Artifact Registry, and Container Registry. In a hypothetical attack scenario, ConfusedFunction could be exploited to leak the Cloud Build service account token via a webhook.
Following responsible disclosure, Google has updated the default behavior such that Cloud Build uses the Compute Engine default service account to prevent misuse. However, it’s worth noting that these changes do not apply to existing instances.
“The ConfusedFunction vulnerability highlights the problematic scenarios that may arise due to software complexity and inter-service communication in a cloud provider’s services,” Tenable researcher Liv Matan said.
“While the GCP fix has reduced the severity of the problem for future deployments, it didn’t completely eliminate it. That’s because the deployment of a Cloud Function still triggers the creation of the aforementioned GCP services. As a result, users must still assign minimum but still relatively broad permissions to the Cloud Build service account as part of a function’s deployment.”
The development comes as Outpost24 detailed a medium-severity cross-site scripting (XSS) flaw in the Oracle Integration Cloud Platform that could be weaponized to inject malicious code into the application.
The flaw, which is rooted in the handling of the “consumer_url” parameter, was resolved by Oracle in its Critical Patch Update (CPU) released earlier this month.
“The page for creating a new integration, found at https://<instanceid>.integration.ocp.oraclecloud.com/ic/integration/home/faces/link?page=integration&consumer_url=<payload>, did not require any other parameters,” security researcher Filip Nyquist said.
“This meant that an attacker would only need to identify the instance-id of the specific integration platform to send a functional payload to any user of the platform. Consequently, the attacker could bypass the requirement of knowing a specific integration ID, which is typically accessible only to logged-in users.”
It also follows Assetnote’s discovery of three security vulnerabilities in the ServiceNow cloud computing platform (CVE-2024-4879, CVE-2024-5178, and CVE-2024-5217) that could be fashioned into an exploit chain in order to gain full database access and execute arbitrary code on the within the context of the Now Platform.
The ServiceNow shortcomings have since come under active exploitation by unknown threat actors as part of a “global reconnaissance campaign” designed to gather database details, such as user lists and account credentials, from susceptible instances.
The activity, targeting companies in various industry verticals such as energy, data centers, software development, and government entities in the Middle East, could be leveraged for “cyber espionage and further targeting,” Resecurity said.
ServiceNow, in a statement shared with The Hacker News said it has “not observed evidence that the activity […] is related to instances that ServiceNow hosts.
“We have encouraged our self-hosted and ServiceNow-hosted customers to apply relevant patches if they have not already done so. We will also continue to work directly with customers who need assistance in applying those patches. It is important to note that these are not new vulnerabilities, but rather were previously addressed and disclosed in CVE-2024-4879, CVE-2024-5217, and CVE-2024-5178.”
(The story was updated after publication to include details about active exploitation of ServiceNow flaws.)
Cybersecurity researchers have uncovered security shortcomings in SAP AI Core cloud-based platform for creating and deploying predictive artificial intelligence (AI) workflows that could be exploited to get hold of access tokens and customer data.
The five vulnerabilities have been collectively dubbed SAPwned by cloud security firm Wiz.
“The vulnerabilities we found could have allowed attackers to access customers’ data and contaminate internal artifacts – spreading to related services and other customers’ environments,” security researcher Hillai Ben-Sasson said in a report shared with The Hacker News.
Following responsible disclosure on January 25, 2024, the weaknesses were addressed by SAP as of May 15, 2024.
In a nutshell, the flaws make it possible to obtain unauthorized access to customers’ private artifacts and credentials to cloud environments like Amazon Web Services (AWS), Microsoft Azure, and SAP HANA Cloud.
They could also be used to modify Docker images on SAP’s internal container registry, SAP’s Docker images on the Google Container Registry, and artifacts hosted on SAP’s internal Artifactory server, resulting in a supply chain attack on SAP AI Core services.
Furthermore, the access could be weaponized to gain cluster administrator privileges on SAP AI Core’s Kubernetes cluster by taking advantage of the fact that the Helm package manager server was exposed to both read and write operations.
“Using this access level, an attacker could directly access other customer’s Pods and steal sensitive data, such as models, datasets, and code,” Ben-Sasson explained. “This access also allows attackers to interfere with customer’s Pods, taint AI data and manipulate models’ inference.”
Wiz said the issues arise due to the platform making it feasible to run malicious AI models and training procedures without adequate isolation and sandboxing mechanisms.
“The recent security flaws in AI service providers like Hugging Face, Replicate, and SAP AI Core highlight significant vulnerabilities in their tenant isolation and segmentation implementations,” Ben-Sasson told The Hacker News. “These platforms allow users to run untrusted AI models and training procedures in shared environments, increasing the risk of malicious users being able to access other users’ data.”
“Unlike veteran cloud providers who have vast experience with tenant-isolation practices and use robust isolation techniques like virtual machines, these newer services often lack this knowledge and rely on containerization, which offers weaker security. This underscores the need to raise awareness of the importance of tenant isolation and to push the AI service industry to harden their environments.”
As a result, a threat actor could create a regular AI application on SAP AI Core, bypass network restrictions, and probe the Kubernetes Pod’s internal network to obtain AWS tokens and access customer code and training datasets by exploiting misconfigurations in AWS Elastic File System (EFS) shares.
“People should be aware that AI models are essentially code. When running AI models on your own infrastructure, you could be exposed to potential supply chain attacks,” Ben-Sasson said.
“Only run trusted models from trusted sources, and properly separate between external models and sensitive infrastructure. When using AI services providers, it’s important to verify their tenant-isolation architecture and ensure they apply best practices.”
The findings come as Netskope revealed that the growing enterprise use of generative AI has prompted organizations to use blocking controls, data loss prevention (DLP) tools, real-time coaching, and other mechanisms to mitigate risk.
“Regulated data (data that organizations have a legal duty to protect) makes up more than a third of the sensitive data being shared with generative AI (genAI) applications — presenting a potential risk to businesses of costly data breaches,” the company said.
They also follow the emergence of a new cybercriminal threat group called NullBulge that has trained its sights on AI- and gaming-focused entities since April 2024 with an aim to steal sensitive data and sell compromised OpenAI API keys in underground forums while claiming to be a hacktivist crew “protecting artists around the world” against AI.
“NullBulge targets the software supply chain by weaponizing code in publicly available repositories on GitHub and Hugging Face, leading victims to import malicious libraries, or through mod packs used by gaming and modeling software,” SentinelOne security researcher Jim Walter said.
“The group uses tools like AsyncRAT and XWorm before delivering LockBit payloads built using the leaked LockBit Black builder. Groups like NullBulge represent the ongoing threat of low-barrier-of-entry ransomware, combined with the evergreen effect of info-stealer infections.”
Cybersecurity researchers are sounding the alarm over an ongoing campaign that’s leveraging internet-exposed Selenium Grid services for illicit cryptocurrency mining.
Cloud security firm Wiz is tracking the activity under the name SeleniumGreed. The campaign, which is targeting older versions of Selenium (3.141.59 and prior), is believed to be underway since at least April 2023.
“Unbeknownst to most users, Selenium WebDriver API enables full interaction with the machine itself, including reading and downloading files, and running remote commands,” Wiz researchers Avigayil Mechtinger, Gili Tikochinski, and Dor Laska said.
“By default, authentication is not enabled for this service. This means that many publicly accessible instances are misconfigured and can be accessed by anyone and abused for malicious purposes.”
Selenium Grid, part of the Selenium automated testing framework, enables parallel execution of tests across multiple workloads, different browsers, and various browser versions.
“Selenium Grid must be protected from external access using appropriate firewall permissions,” the project maintainers warn in a support documentation, stating that failing to do so could allow third-parties to run arbitrary binaries and access internal web applications and files.
Exactly who is behind the attack campaign is currently not known. However, it involves the threat actor targeting publicly exposed instances of Selenium Grid and making use of the WebDriver API to run Python code responsible for downloading and running an XMRig miner.
It starts with the adversary sending a request to the vulnerable Selenium Grid hub with an aim to execute a Python program containing a Base64-encoded payload that spawns a reverse shell to an attacker-controlled server (“164.90.149[.]104”) in order to fetch the final payload, a modified version of the open-source XMRig miner.
“Instead of hardcoding the pool IP in the miner configuration, they dynamically generate it at runtime,” the researchers explained. “They also set XMRig’s TLS-fingerprint feature within the added code (and within the configuration), ensuring the miner will only communicate with servers controlled by the threat actor.”
The IP address in question is said to belong to a legitimate service that has been compromised by the threat actor, as it has also been found to host a publicly exposed Selenium Grid instance.
Wiz said it’s possible to execute remote commands on newer versions of Selenium and that it identified more than 30,000 instances exposed to remote command execution, making it imperative that users take steps to close the misconfiguration.
“Selenium Grid is not designed to be exposed to the internet and its default configuration has no authentication enabled, so any user that has network access to the hub can interact with the nodes via API,” the researchers said.
“This poses a significant security risk if the service is deployed on a machine with a public IP that has inadequate firewall policy.”
Selenium, in an advisory released on July 31, 2024, urged users to upgrade their instances to the latest version to mitigate against the threat.
“Selenium Grid by default doesn’t have any authentication as the assumption has always been that we want you to put this behind a secure network to prevent people from abusing your resources,” it said. “Another way to combat this is to use a cloud provider to run your Selenium Grid.”
Are smartphones less secure than PCs? The answer to that is, they’re different. They face different security threats. Yet they certainly share one thing in common — they both need protection.
So, what makes a smartphone unique when it comes to security? And how do you go about protecting it? We’ll cover both here.
Apps, spam texts, and other smartphone vulnerabilities
Several facts of life about smartphones set them apart when it comes to keeping your devices safer. A quick rundown looks like this:
First off, people keep lots of apps on their phones. Old ones, new ones, ones they practically forgot they had. The security issue that comes into play there is that any app on a phone is subject to vulnerabilities.
A vulnerability in just one of the dozens of apps on a phone can lead to problems. The adage of “the weakest link” applies here. The phone is only as secure as its least secure app. And that goes for the phone’s operating system as well.
Additionally, app permissions can also introduce risks. Apps often request access to different parts of your phone to work — such as when a messenger app asks for access to contacts and photos. In the case of malicious apps, they’ll ask for far more permissions than they need. A classic example involves the old “flashlight apps” that invasively asked for a wide swath of permissions. That gave the hackers all kinds of info on users, including things like location info. Today, the practice of malicious, permission-thirsty apps continues with wallpaper apps, utility apps, games, and more.
As for other malicious apps, sometimes people download them without knowing. This often happens when shopping in third-party app stores, yet it can happen in legit app stores as well — despite rigorous review processes from Apple and Google. Sometimes, hackers sneak them through the review process for approval. These apps might include spyware, ransomware, and other forms of malware.
Many people put their smartphones to personal and professional use.[i] That might mean the phone has access to corporate apps, networks, and data. If the phone gets compromised, those corporate assets might get compromised too. And it can work in the other direction. A corporate compromise might affect an employee’s smartphone.
More and more, our phones are our wallets. Digital wallets and payment apps have certainly gained popularity. They speed up checkout and make splitting meals with friends easy. That makes the prospect of a lost or stolen phone all the more serious. An unsecured phone in the hands of another is like forking over your wallet.
Lastly, spam texts. Unique to phones are the sketchy links that crop up in texting and messaging apps. These often lead to scam sites and other sites that spread malware.
With a good sense of what makes securing your smartphone unique, let’s look at several steps you can take to protect it.
How to protect your smartphone
Update your phone’s apps and operating system
Keeping your phone’s apps and operating system up to date can greatly improve your security. Updates can fix vulnerabilities that hackers rely on to pull off their malware-based attacks. it’s another tried and true method of keeping yourself safer — and for keeping your phone running great too.
Lock your phone
With all that you keep and conduct on your phone, a lock is a must. Whether you have a PIN, passcode, or facial recognition available, put it into play. The same goes for things like your payment, banking, and financial apps. Ensure you have them locked too.
Avoid third-party app stores
As mentioned above, app stores have measures in place to review and vet apps that help ensure they’re safe and secure. Third-party sites might very well not, and they might intentionally host malicious apps as part of a front. Further, legitimate app stores are quick to remove malicious apps from their stores once discovered, making shopping there safer still.
Review apps carefully
Check out the developer — have they published several other apps with many downloads and good reviews? A legit app typically has many reviews. In contrast, malicious apps might have only a handful of (phony) five-star reviews. Lastly, look for typos and poor grammar in both the app description and screenshots. They could be a sign that a hacker slapped the app together and quickly deployed it.
Go with a strong recommendation.
Yet better than combing through user reviews yourself is getting a recommendation from a trusted source, like a well-known publication or app store editors themselves. In this case, much of the vetting work has been done for you by an established reviewer. A quick online search like “best fitness apps” or “best apps for travelers” should turn up articles from legitimate sites that can suggest good options and describe them in detail before you download.
Keep an eye on app permissions
Another way hackers weasel their way into your device is by getting permissions to access things like your location, contacts, and photos — and they’ll use malicious apps to do it. If an app asks for way more than you bargained for, like a simple puzzle game that asks for access to your camera or microphone, it might be a scam. Delete the app.
Learn how to remotely lock or erase your smartphone
So what happens if your phone ends up getting lost or stolen? A combination of device tracking, device locking, and remote erasing can help protect your phone and the data on it. Different device manufacturers have different ways of going about it, but the result is the same — you can prevent others from using your phone. You can even erase it if you’re truly worried that it’s gone for good. Apple provides iOS users with a step-by-step guide, and Google offers a guide for Android users as well.
DigiCert has started revoking thousands of certificates impacted by a recently discovered verification issue, but some customers in critical infrastructure and other sectors are asking for more time.
The certificate authority (CA) informed customers on July 29 of an incident related to domain validation, saying that it needs to revoke some certificates within 24 hours due to strict CA/Browser Forum (CABF) rules.
The company initially said roughly 0.4% of applicable domain validations were impacted. A DigiCert representative clarified in discussions with stakeholders that 83,267 certificates and 6,807 subscribers are affected.
DigiCert said some of the impacted customers were able to quickly reissue their certificates, but others would not be able to do so within the 24-hour time frame.
“Unfortunately, many other customers operating critical infrastructure, vital telecommunications networks, cloud services, and healthcare industries are not in a position to be revoked without critical service interruptions. While we have deployed automation with several willing customers, the reality is that many large organizations cannot reissue and deploy new certificates everywhere in time,” said Jeremy Rowley, CISO at DigiCert.
DigiCert said in an updated notification that it has been working with browser representatives and customers in an effort to delay revocations under exceptional circumstances in order to avoid disruption to critical services.
However, the company highlighted that “all certificates impacted by this incident, regardless of circumstances, will be revoked no later than Saturday, August 3rd 2024, 19:30 UTC.”
Rowley noted that some customers have initiated legal action against DigiCert in an attempt to block the revocation of certificates.
The certificates are being revoked due to an issue related to the process used by DigiCert to validate that a customer requesting a TLS certificate for a domain is actually the owner or administrator of that domain.
One option is for customers to add a DNS CNAME record with a random value provided by DigiCert to their domain. The random value provided by DigiCert is prefixed by an underscore character to prevent collisions between the value and the domain name. However, the underscore prefix was not added in some cases since 2019.
In order to comply with CABF rules, DigiCert has to revoke certificates with an issue in their domain validation within 24, without exception.
Andrew Ayer, founder of SSLMate and an expert in digital certificates, believes that DigiCert’s public notification about this incident “gets the security impact of the noncompliance completely wrong”.
“[…] this is truly a security-critical incident, as there is a real risk […] that this flaw could have been exploited to get unauthorized certificates. Revocation of the improperly validated certificates is security-critical,” Ayer said.
The European Union’s world-first artificial intelligence law formally took effect on Thursday, marking the latest milestone in the bloc’s efforts to regulate the technology.
Officials say the Artificial Intelligence Act will protect the “fundamental rights” of citizens in the 27-nation bloc while also encouraging investment and innovation in the booming AI industry.
Years in the making, the AI Act is a comprehensive rulebook for governing AI in Europe, but it could also act as a guidepost for other governments still scrambling to draw up guardrails for the rapidly advancing technology.
The AI Act covers any product or service offered in the EU that uses artificial intelligence, whether it’s a platform from a Silicon Valley tech giant or a local startup. The restrictions are based on four levels of risk, and the vast majority of AI systems are expected to fall under the low-risk category, such as content recommendation systems or spam filters.
“The European approach to technology puts people first and ensures that everyone’s rights are preserved,” European Commission Executive Vice President Margrethe Vestager said. “With the AI Act, the EU has taken an important step to ensure that AI technology uptake respects EU rules in Europe.”
The provisions will come into force in stages, and Thursday’s implementation date starts the countdown for when they’ll kick in over the next few years.
AI systems that pose “unacceptable risk,” such as social scoring systems that influence how people behave, some types of predictive policing and emotion recognition systems in schools and workplaces, will face a blanket ban by February.
Rules covering so-called general-purpose AI models like OpenAI’s GPT-4 system will take force by August 2025.
Brussels is setting up a new AI Office that will act as the bloc’s enforcer for the general purpose AI rules.
OpenAI said in a blog post that it’s “committed to complying with the EU AI Act and we will be working closely with the new EU AI Office as the law is implemented.”
By mid-2026, the complete set of regulations, including restrictions on high-risk AI such as systems that decide who gets a loan or that operate autonomous robots, will be in force.
There’s also a fourth category for AI systems that pose a limited risk, and face transparency obligations. Chatbots must be informed that they’re interacting with a machine and AI-generated content like deepfakes will need to be labelled.
Companies that don’t comply with the rules face fines worth as much as 7% of their annual global revenue.
Privacy-focused search engine DuckDuckGo has been blocked in Indonesia by its government after citizens reportedly complained about pornographic and online gambling content in its search results.
The government’s choice to block DuckDuckGo isn’t surprising considering the cultural and religious context, with Indonesia being a Muslim country where gambling is prohibited and porn is viewed as morally unacceptable.
The government has previously blocked numerous pornography sites, Reddit, and Vimeo, and imposed temporary or partial restrictions on Tumblr, Telegram, TikTok, Netflix, and Badoo.
DuckDuckGo has now confirmed to BleepingComputer that Indonesia blocked its search engine in the country and that it has no means to respond to it.
“We can confirm that DuckDuckGo has been blocked in Indonesia due to their censorship policies. Unfortunately, there is no current path to being unblocked, similar to how we’ve been blocked in China for about a decade now,” DuckDuckGo told BleepingComputer.
At the same time, Google Search remains accessible in Indonesia, which suggests that either the tech giant has implemented effective self-censorship mechanisms for its local search engine or its size makes blocking too disruptive for internet usage in the country.
Indonesians have resorted to using VPN software to bypass the government’s restrictions. However, the Indonesian government plans to block free VPNs, making gaining access to blocked sites costly.
Free VPNs next
Virtual Private Network (VPN) tools are commonly used to bypass censorship imposed by governments and internet service providers.
When using VPNs, users can make connections from other countries to once again access DuckDuckGo, but free offerings may soon be removed.
Minister of Communication and Information Budi Arie Setiadi stated that the government intends to restrict access to free VPN tools, as they know these are used to access blocked online gambling portals.
“Yesterday, Mr. Hokky (Ministry’s Director General of Informatics Applications) had a meeting with Mr. Wayan (Ministry’s Director General of Postal and Information Technology Operations), and we will shut down free VPNs to reduce access to networks for the general public to curb the spread of online gambling,” stated Setiadi on June 31, 2024.
“I specifically have to include the issue of online gambling to make it clear that this is the darkest side of digitalization.”
The same ministry announcement highlighted the risks of free VPN services, underlining personal data theft, malware infections, and making internet connectivity slow or unreliable.
React and its virtual DOM paradigm has been at the forefront of frontend development for a decade now, but there’s been a swing towards simplicity and web-native features in more recent frameworks. Astro is a great example; and it also now has the support of Netlify, a leading player in the current web landscape.
Earlier this month Netlify announced Astro as its “Official Deployment Partner,” which in practice means it will contribute $12,500 each month “towards the ongoing open source maintenance and development of Astro.”
As Netlify CEO Matt Biilmann noted, Astro was “the first framework to popularize the idea of island architecture, where islands are interactive widgets floating in a sea of otherwise static, lightweight, server-rendered HTML.” As part of the new official partnership, Netlify will help Astro roll out a related new feature: Server Islands. Astro defines this as a “solution to integrate high-performance static HTML and dynamic server-generated components together.”
Astro concept drawing of server islands.
How Is Astro Different to React Frameworks?
We’ll get back to server islands shortly. But first, let’s look at why Astro has become a trending framework. Conceptually, the main difference between Astro and the React-based frameworks that came before it is this: most of the work is done server-side, instead of client-side. Here’s how Astro’s founders explained it in their introductory post, back in June 2021:
“Astro renders your entire site to static HTML during the build. The result is a fully static website with all JavaScript removed from the final page. No monolithic JavaScript application required, just static HTML that loads as fast as possible in the browser regardless of how many UI components you used to generate it.”
Astro is perhaps closest to a static site generator, like Eleventy and Hugo, but it also cunningly incorporates other approaches too — including React itself. “In Astro, you compose your website using UI components from your favorite JavaScript web framework (React, Svelte, Vue, etc),” wrote the founders in 2021. The trick was, that all of that complexity was rendered into HTML in the build phase, meaning it was never foisted onto the user.
Astro creator Fred K. Schott demoed the product in April 2021.
But undoubtedly the key to Astro’s subsequent success is the “islands architecture.” That’s because, for a web application of any scale, chances are JavaScript will be needed at some point. But whereas previous frameworks, like Angular and Next.js, focused on client-side rendering — the so-called single-page application (SPA) approach — Astro wanted to limit client-side rendering to certain parts of an app (the “islands”). While both Angular and Next.js can implement partial hydration and server-side rendering, Astro’s architecture inherently avoids client-side JavaScript by default, unless explicitly required.
“When a component needs some JavaScript, Astro only loads that one component (and any dependencies),” explained the Astro founders. “The rest of your site continues to exist as static, lightweight HTML.”
Astro credited Jason Miller with coining “islands architecture,” pointing to an August 2020 article on Miller’s blog. He in turn credited Etsy frontend architect Katie Sylor-Miller for coining the “Component Islands” pattern in 2019.
There was some skepticism about “web islands” when they were first discussed in 2021.
In April 2021, Astro creator Fred K. Schott demonstrated Astro for the first time. He acknowledged that “partial hydration” (a key part of the islands architecture) had been difficult to achieve in practice to this point. He said that frameworks like Next.js and Gatsby had to try and “take this application and pull it apart” if they wanted to implement partial hydration. That could cause significant problems, so Astro took a completely different approach.
“What we try and do is, by default, it’s all server-rendered,” said Schott in the April 2021 podcast. “So by default, you’re speaking this language of a server-rendered document, and then individual components, instead of being pulled out of an application, are actually being injected into a document. So it’s a totally different kind of static-first approach, where the result is that you actually have to opt into all of your payloads, and everything becomes much lighter as a result.”
Server Islands
Fast forward to 2024 and Astro has become a rising web framework. As well as the technical advantages outlined above, Astro offers a kind of ‘back to basics’ approach to web development that harkens back to early Web 2.0 frameworks, like Ruby on Rails and Django, which were also server-rendered. Now that Astro has become a viable alternative to the likes of Next.js, it is trying to expand its capabilities. Enter “Server Islands.”
In its announcement post, Astro referenced the original islands architecture as “interactive client-side components.” With Static Islands, the idea is to add “dynamic server-generated components” to the mix as well. In practice, you use “server:defer” to defer running a particular component until after the page loads. So it’s a kind of caching mechanism, similar perhaps to Next.js “partial prerendering” — or at least “solving the same problem,” as Schott said on X.
Server islands comparison to Next.js tech.
In a recent four-and-a-half-hour podcast with Ryan Carniato, the creator of Solid.js, Astro developer Matthew Phillips discussed Server Islands. “What it really is, is a way to differentiate types of content to run at different times,” he explained, adding later that Server Islands “essentially cache different parts of your page differently.”
Carniato noted that when Astro first came out, they positioned the client-side islands as being “interactive,” whereas the rest of the HTML was “non-interactive.” He pointed out that Astro is now using the word “static” to indicate the non-changing content, and “dynamic” to mean a server-side island — for example, an “x rooms left” button on an Airbnb-type website, which requires checking with a database.
Ryan Carniato and Matthew Phillips discuss server islands.
Note that although Server Islands are different to traditional Astro islands, a component can be both at the same time. Netlify explains this well in a recent blog post:
“It’s worth clarifying that Astro Server Islands are different to standard Astro Islands, which improve performance by allowing you to selectively ‘hydrate’ components, i.e. load JavaScript only for components that need it, instead of making the entire page interactive. In fact, a component can be both an Island and a Server Island!”
Back to the Future
One can’t help but wonder whether Astro is slowly falling into the same trap as Next.js, in that it will get progressively more complex over time. But the concept of Server Islands isn’t that difficult to grok, so currently it feels like a sensible extension of the core “islands architecture” concept of Astro.
What I love about Astro is that it gets us back to that server-based paradigm that we grew up with on the web in the 1990s (at least, those of us of a certain vintage), and which early Web 2.0 frameworks like Ruby on Rails and Django extended. But Astro adds component-based development to the mix, including options to use React and Vue, which makes it an entirely modern approach.
Ultimately, anything that takes the bulk of the JavaScript load away from the client (read: end users) is a good thing, and Astro is certainly helping in that regard.
“After giving it a lot of thought, we made the decision to discontinue new access to a small number of services, including AWS CodeCommit,” AWS Chief Evangelist Jeff Barr wrote, sharing a prepared message on the X social media service Tuesday.
Although existing customers can continue to use CodeCommit for the time being, AWS has stopped accepting new customers. And it has not given a date on when the service would be shuttered.
“While we are no longer onboarding new customers to these services, there are no plans to change the features or experience you get today, including keeping them secure and reliable,” Barr wrote in an extended Tweet. “We also support migrations to other AWS or third-party solutions better aligned with your evolving needs.”
How to delete a CodeCommit repository — after migrating to another service (AWS)
“After migration, you have the option to continue to use your current AWS CodeCommit repository, but doing so will likely require a regular sync operation between AWS CodeCommit and the new repository provider,” the cloud giant provider advised.
Nonetheless, the service had trouble gaining a foothold in the competitive code repository market, despite the natural appeal for AWS shops to stick with AWS for additional services.
TNS Analyst Lawrence Hecht noted that, in last year’s JetBrains survey, 3.2% of the developers surveyed used CodeCommit. Even among developers whose company primarily uses AWS for the cloud, only 9% used AWS CodeCommit.
Those same AWS-centric accounts were much more likely to say their company was using BitBucket (39%), GitLab (45%) and GitHub (63%)
“That is not a large user base, but it will be interesting to see where those people will migrate to,” noted Hecht in a Slack message.
https://datawrapper.dwcdn.net/p0BfG/1
One place where AWS CodeCommit has a strong userbase was Japan. In the JetBrains survey, 11% of developers said their company uses it, a larger user base than BitBucket in that market.
Despite the marginal use of CodeCommit, many observers still had feelings about the matter.
“Given AWS is a competitor to Azure, it’s so odd to see AWS making a business case for their customers to move” to Microsoft, wrote Gergely Orosz, author of the Pragmatic Engineer newsletter, in an X thread.
“To me, this is a clear sign to not adopt any dev-related tooling from AWS. It’s not the business they want to be in,” replied Acorn Labs chief architect and co-founder Darren Shepherd.
For GitLab, AWS shuttering CodeCommit is a sign that the market for code hosting has matured.
“The market has moved from point solutions to platforms that address the entire software development lifecycle,” wrote Emilio Salvador, GitLab vice president for strategy and developer relations, in a statement. “Buyers are now looking to platforms that provide one workflow that unifies developer, security, and operations teams with integrated native security.”
GitLab has set up two options for migrations from CodeCommit, using either self-managed GitLab or through the GitLab.com hosted service.
“Self-managed customers can install, administer, and maintain their GitLab instance on bare metal, VMs, or containers. GitLab.com requires no installation,” Salvador explained.
Other companies in the space are focusing on how their products can help in the transition.
“Migration to a new source code management tool is always challenging, The right considerations and migration strategies can significantly help with the process,” wrote Patrick Wolf, principal product manager at Harness, a DevOps software provider, in an e-mail to TNS. “Some important considerations for selecting a new Source Code Manager are integration with a DevOps platform, security and governance features, and developer productivity features.”
The Registry Editor is a powerful application that allows you to access and edit the configuration settings of the Windows operating system.
The Windows Registry is a database containing various settings used by the operating system and installed software applications.
However, it is essential to be careful when using the Registry Editor, as making incorrect changes to the Registry can cause serious problems with your system, including preventing it from booting correctly.
The Windows Registry database stores the configuration options and settings for the Windows operating system and software installed on your computer.
The Registry is organized in a hierarchical structure containing keys and values, with five different ‘root’ keys at the top, as shown below, that serve a particular purpose.
The Windows Registry Editor showing the five root keys Source: BleepingComputer
The five different root keys in the Windows registry and their purposes are:
HKEY_CLASSES_ROOT (HKCR): This key stores information about file associations and OLE object classes.
HKEY_CURRENT_USER (HKCU): This key stores information about the current user’s settings and a specific user’s preferences for various applications.
HKEY_LOCAL_MACHINE (HKLM): This key stores information that affects the entire computer, regardless of the logged-in user. These settings are for the computer’s hardware, operating system configuration, and software settings that affect all users.
HKEY_USERS (HKU): This key stores information about all users who have logged on to the computer.
HKEY_CURRENT_CONFIG (HKCC): This key stores information about the current hardware configuration of the computer.
For the most part, you will be modifying keys and values under the HKCU and HKLM root keys.
Registry keys are like folders containing other keys and values used to organize and group related settings.
For example, the HKEY_CURRENT_USER key contains settings for the current user account, such as a user’s desktop wallpaper, installed application preferences, and personal settings.
While keys are like folders, Registry values are the files stored within them, containing the specific settings for a particular key. They can have different data types, including text, numbers, and binary data.
There are several different types of registry value data types:
REG_SZ – A string value that contains text data, such as a username or folder path.
REG_DWORD – A numeric value that contains a 32-bit integer.
REG_QWORD – A numeric value that contains a 64-bit integer.
REG_BINARY – A value that contains binary data, such as an image or sound file.
REG_MULTI_SZ – A string value that contains multiple strings separated by null characters. This is often used for lists or arrays of values.
Each registry value type is used for a specific purpose, and understanding them can help you better manage and customize your Windows operating system.
Viewing Registry keys and values in the Windows Registry Editor Source: BleepingComputer
However, for the most part, when editing the Registry, you will be modifying REG_SZ values for text data and REG_DWORD for numeric data, as they are the most common data types used to stored user-editable data.
Using the Windows Registry Editor
The Windows Registry Editor is a software application created by Microsoft and built into all versions of Windows that allows you to edit the data in the Registry.
The Registry Editor application is located at C:\Windows\regedit.exe,and for the most part, requires administrative privileges to use it properly.
To open the Registry Editor, press the Windows key + R to open the Run dialog box. Next, type “regedit” in the search box and press Enter. If you are shown a prompt asking if you would like to allow the program to make changes, select ‘Yes‘ to continue.
When the Registry Editor is opened, you will see that the window is divided into two panes. The left pane displays a hierarchical tree structure of the Registry’s various keys (folders) and subkeys (subfolders).
The right pane displays the values and data associated with the selected key in the left pane.​
The Windows Registry Editor Source: BleepingComputer
To open a specific Registry key, use the left pane to navigate to the key you want to edit. Then expand a key and click on the plus sign (+) next to it.
To collapse a key, click the minus sign (-) next to it.
When you click on a key in the left pane, the values stored within it will be shown in the right pane.
Now that we know how to navigate the Windows Registry let’s learn how to modify data stored within it.
CREATE A NEW REGISTRY KEY
When configuring new settings in the Windows Registry, you may need to create a key at some point.
Use these steps to create a new key in the Registry:
Right-click on the key you want to create a new subkey under in the left pane.
Select New -> Key.
Enter a name for the new key and press Enter.
CREATING A REGISTRY VALUE
As Registry values contain the data that configure how an application or Windows works, it is common to need to create Registry values.
Use these steps to create a Registry value:
Navigate to the key where you want to create the value.
Right-click on the key and select “New” and then select the type of value you want to create. The kinds of values you can make are explained in the previous section.
Give the new value a name by typing it in the box that appears.
Double-click on the new value to edit its data.
Enter the desired value data and click OK.
RENAMING REGISTRY KEY
Sometimes you may need to rename a Registry value, such as when introducing a typo.
To rename a Registry key, please follow these steps:
Navigate to the key you want to rename.
Right-click the key and select Rename.
Enter the new name for the key in the editable field.
Click anywhere to save the changes.
RENAMING A REGISTRY VALUE
Sometimes you may need to rename a Registry value, such as when introducing a typo.
To rename a Registry value, please follow these steps:
Right-click the value you want to rename in the right pane and select Rename.
Enter the new name for the key in the editable field.
Click anywhere to save the changes.
EDITING REGISTRY VALUE DATA
To make changes to a Registry value, follow these steps:
Double-click on the value you want to edit in the right pane.
The Edit dialog box will appear.
Enter the new value for the key in the ‘Value data’ field.
Click OK to save your changes.
EXPORT A REGISTRY KEY
It is possible to export Registry keys and all their subkeys and values to a registry file.
A registry file ends with .reg, and when you double-click on one in Windows, it will import the data back into the Registry. Exporting a registry key helps create a backup before you make changes to the Registry.
Right-click on the key you want to export in the left pane.
Select Export.
Choose a location to save the exported key and give it a name.
Click Save.
IMPORT A REGISTRY KEY
If you had previously exported a key, you could import its data into the Registry by importing the file using these steps:
Click on File -> Import.
Navigate to the location where you saved the exported key.
Select the key file and click Open.
DELETE A REGISTRY KEY
If you need to delete a Registry key, use the following steps.
Right-click on the key you want to delete in the left pane.
Select ‘Delete‘from the context menu.
Confirm that you want to delete the key by clicking Yes.
Note: If you delete a key, all subkeys and values underneath them will be deleted too!
Note 2: You should only delete a registry key if you know it will not cause issues with your computer!
DELETE A REGISTRY VALUE
If you need to delete a Registry value, use the following steps.
Right-click on the value you want to delete in the right pane.
Select ‘Delete‘ from the context menu.
Confirm that you want to delete the value by clicking Yes.
Note: You should only delete a registry value if you know it will not cause issues with your computer
When done using the Registry Editor, you can close it by clicking on the X in the Window or clicking on File > Exit.
With these steps, you should now be able to use the Windows Registry Editor to navigate and edit the Registry.
However, it is vital to be careful when making changes to the Registry, as incorrect changes can cause severe problems with your system.
BitTorrent is often characterized as a decentralized file-sharing technology. However, its reliance on centralized indexes runs contrary to this idea. Over the years, several ‘indestructible’ alternatives have been proposed, including the relatively new Bitmagnet software. With Bitmagnet, people can run their own private BitTorrent index, relying on DHT and the BEP51 protocol.
When Bram Cohen released the first version of BitTorrent in 2002, it sparked a file-sharing revolution.
At the time bandwidth was a scarce resource, making it impossible to simultaneously share large files with millions of people over the Internet. BitTorrent not only thrived in that environment, the protocol remains effective even to this day.
BitTorrent transfers rely on peer-to-peer file-sharing without a central storage location. With updated additions to the protocol, such as the BitTorrent Distributed Hash Table (DHT), torrent files no longer require a tracker server either, making it decentralized by nature.
In theory, it doesn’t always work like that though. People who use BitTorrent, for research purposes or to grab the latest Linux distros, often use centralized search engines or indexes. If these go offline, the .torrent files they offer go offline too.
Decentralizing Torrents
This problem isn’t new and solutions have been around for quite a few years. There’s the University-sponsored Tribler torrent client, for example, and the BitTorrent protocol extension (BEP51), developed by ‘The 8472’, that also helps to tackle this exact problem.
BEP51 makes it possible to discover and collect infohashes through DHT, without the need for a central tracker. These infohashes can be converted to magnet links and when paired with relevant metadata, it’s possible to create a full BitTorrent index that easily rivals most centralized torrent sites.
Some centralized torrent sites, such as BTDigg, have already done just that. However, the beauty of the proposition involving DHT is that centralized sites are not required to act as search engines. With the right code, anyone can set up their own personalized and private DHT crawler, torrent index, and search engine.
Bitmagnet: A Private Decentralized Torrent Index
Bitmagnet is a relatively new self-hosted tool that does exactly that. The software, which is still in an early stage of development, was launched publicly a few months ago.
“The project aims to reduce reliance on public torrent sites that are prone to takedown and expose users to ads and malware,” Mike, the lead developer, tells us.
Those who know how to create a Docker container can have an instance up and running in minutes and for the privacy conscious, the docker-compose file on GitHub supports VPNs via Gluetun. Once Bitmagnet is up and running, it starts collecting torrent data from DHT, neatly classifies what it finds, and makes everything discoverable through its own search engine.Bitmagnet UI
Decentralization is just one of the stated advantages. The developer was also positively surprised by the sheer amount of content that was discovered and categorized through Bitmagnet. This easily exceeds the libraries of most traditional torrent sites.
“Run it for a month and you’ll have a personal index and search engine that dwarfs the popular torrent websites, and includes much content that can often only be found on difficult-to-join private trackers,” Mike tells us.
After running the software for four months, the developer now has more than 12 million indexed torrents. However, other users with more bandwidth and better connections have many more already. This also brings us to one of the main drawbacks; a lack of curation.
Curation
Unlike well-moderated torrent sites, Bitmagnet adds almost any torrent it finds to its database. This includes mislabeled files, malware-ridden releases, and potentially illegal content. The software tries to limit abuse by filtering metadata for CSAM content, however.
There are plans to add more curation by adding support for manual postings and federation. That would allow people with similar interests to connect, acting more like a trusted community. However, this is still work in progress.
Another downside is that it could take longer to index rare content, as it has to be discovered first. Widely shared torrents tend to distribute quickly over DHT, but rare releases will take much longer to be picked up. In addition, users may occasionally stumble upon dead or incomplete torrents.
Thus far, these drawbacks are not stopping people from trying the software.
While Bitmagnet is only out as an “alpha” release it’s getting plenty of interest. The Docker image has been downloaded nearly 25k times and the repository has been starred by more than a thousand other developers so far.
Caution is Advised!
Mike doesn’t know how many people are running an instance or how they’re using them. Bitmagnet is designed and intended for people to run on their own computer and network, but people could turn it into a public-facing search engine as well.
Running a public search engine comes with legal risks of course. Once there’s serious traffic, that will undoubtedly alert anti-piracy groups.
Even those who use the software privately to download legitimate content might receive complaints. By crawling the DHT, the software presents itself as a torrent client. While it doesn’t download any content automatically, some rudimentary anti-piracy tracking tools might still (incorrectly) flag this activity.
There are no examples of this happening at the moment, but the potential risk is why Bitmagnet advises users to opt for VPN routing.
Impossible to Shut Down
All in all, Bitmagnet is an interesting tool that uses some of BitTorrent’s underutilized powers, which have become increasingly rare in recent years.
The idea behind Bitmagnet is similar to Magnetico, which first came out in 2017. While that no longer appears to be actively maintained, it remains available on GitHub. During these years, we haven’t seen any takedown notices targeting the software.
Mike hopes that his project will be spared from copyright complaints too. The developer sees it simply as a content-neutral tool, much like a web browser.
“I hope that the project is immune from such issues, because the source code contains no copyright infringing material. How people choose to use the app is up to them – if you access copyrighted content using a web browser or BitTorrent client, that does not make the vendors of those apps liable.”
“Bitmagnet cannot be ‘taken down’ – even if the GitHub repository were threatened by an illegitimate takedown request, the code can easily be hosted elsewhere,” Mike concludes.




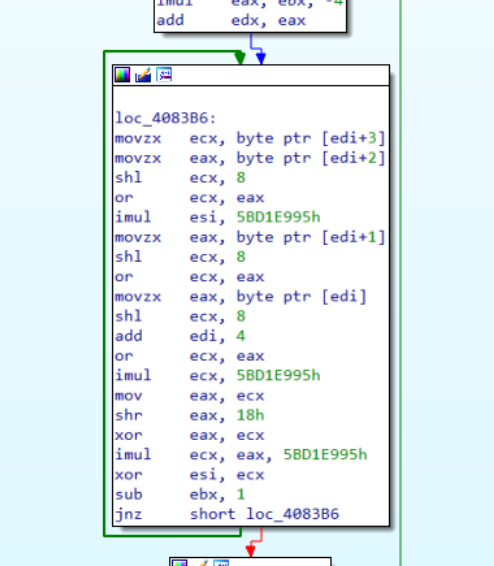 Figure 4: MurMur2 hashing routine
Figure 4: MurMur2 hashing routine

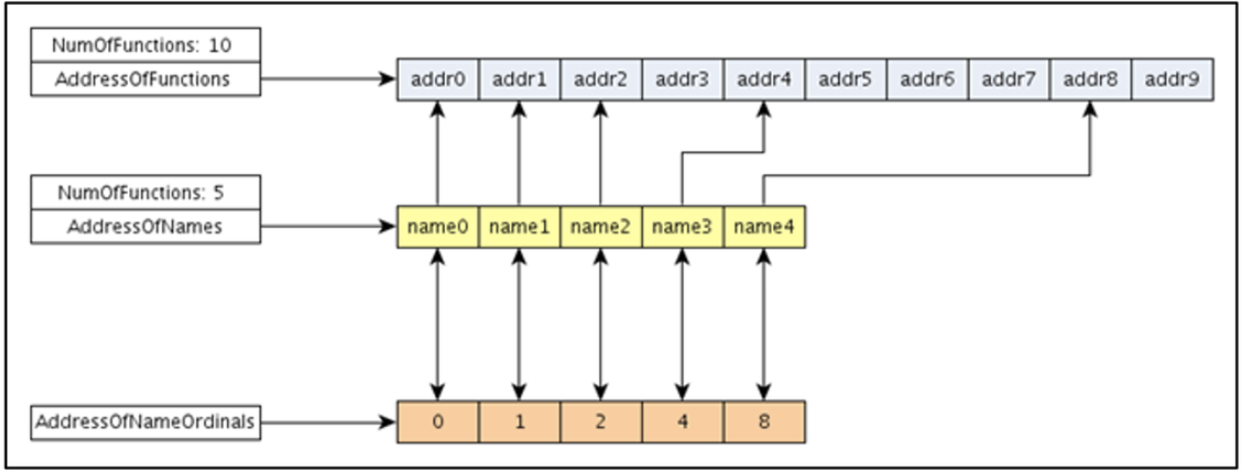























































































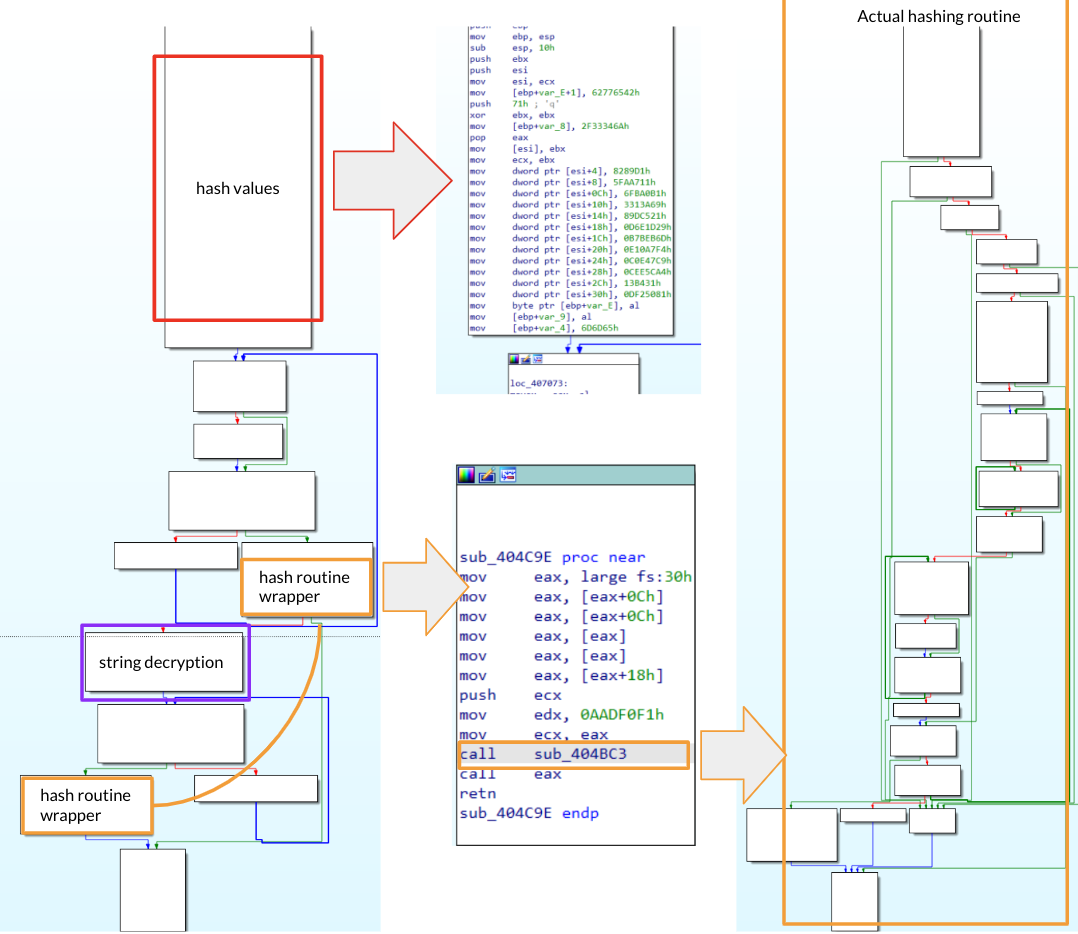
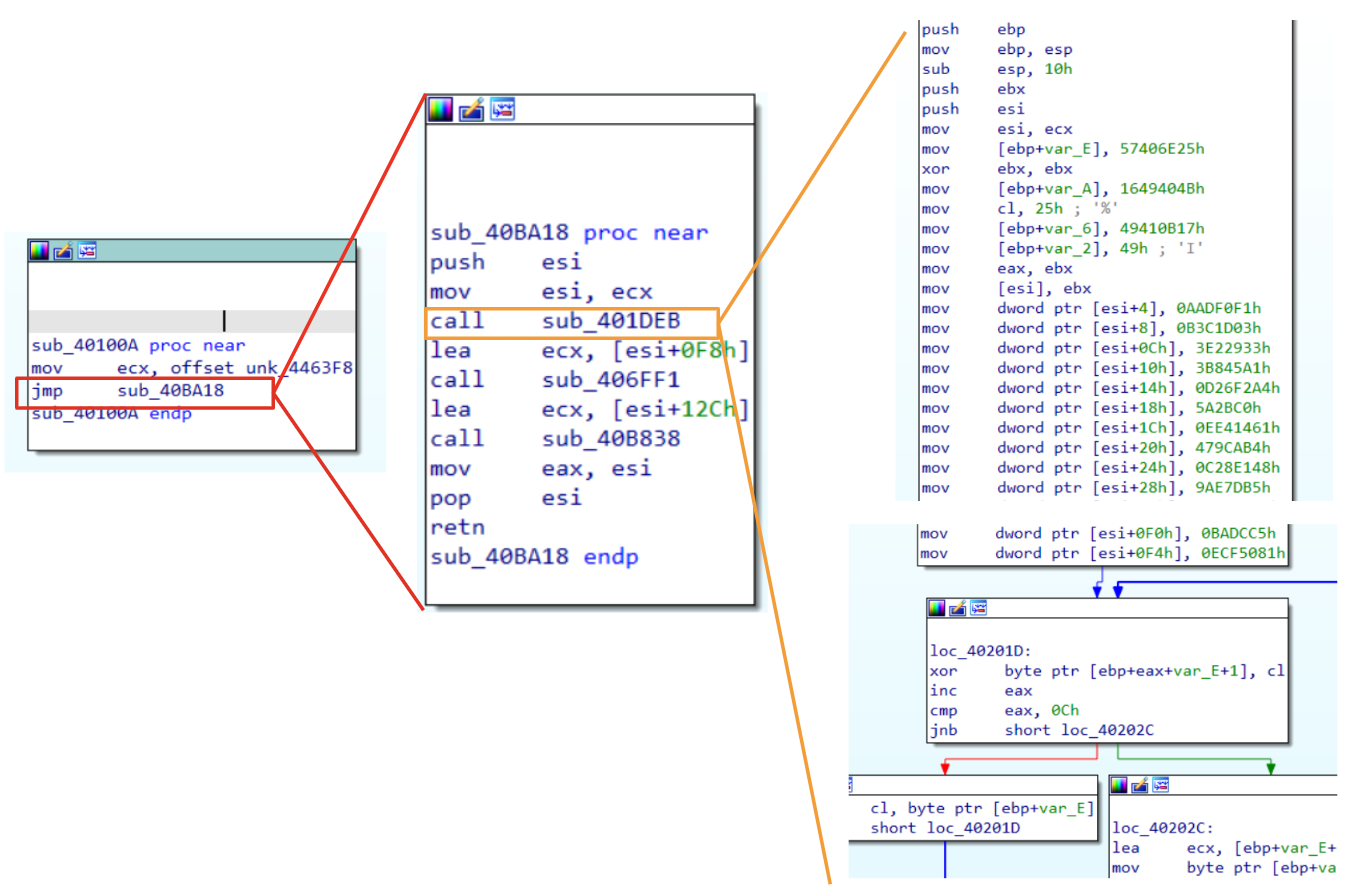
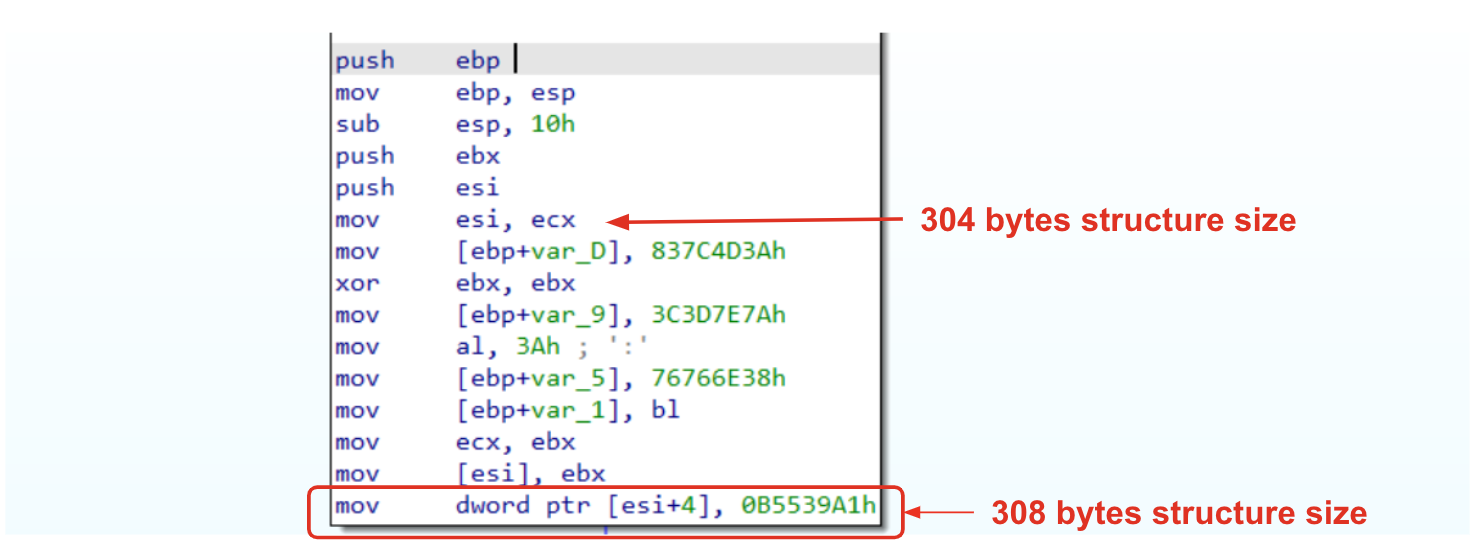
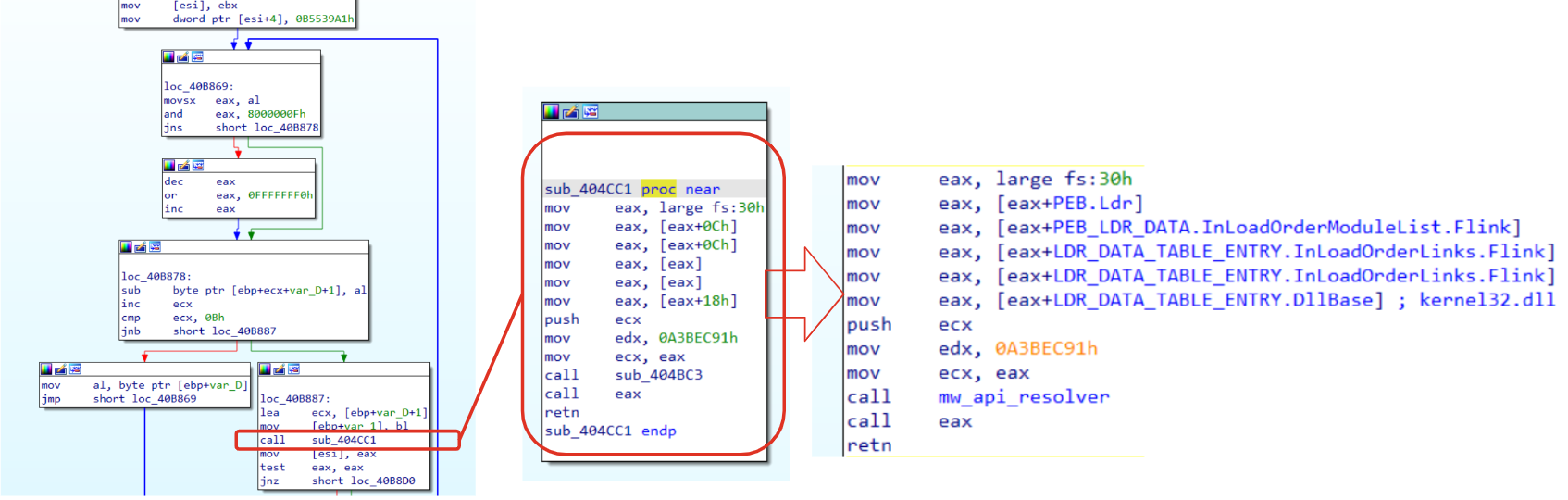
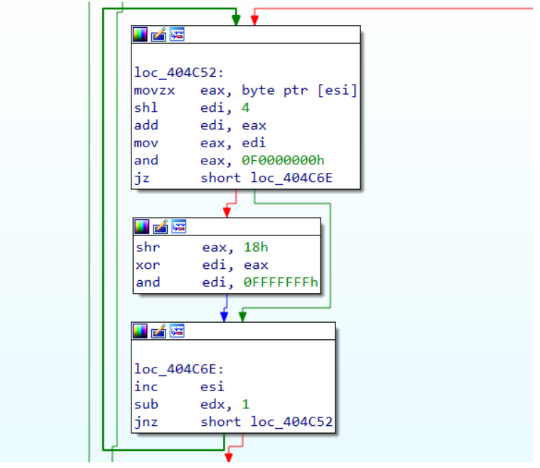
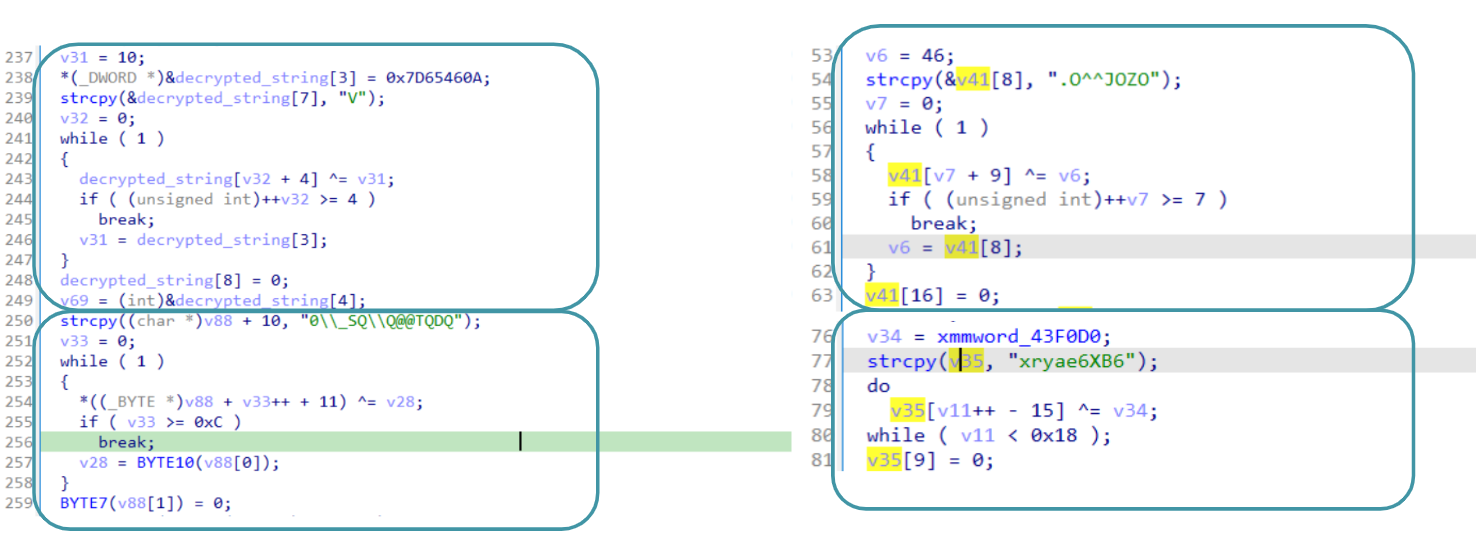






















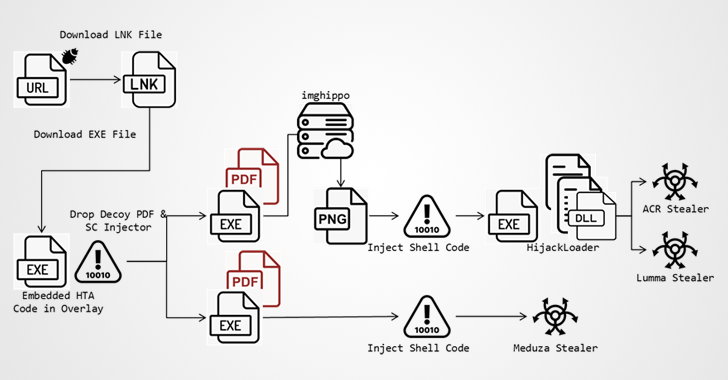


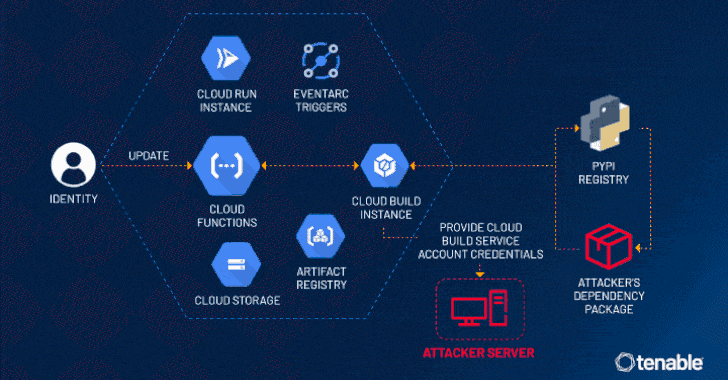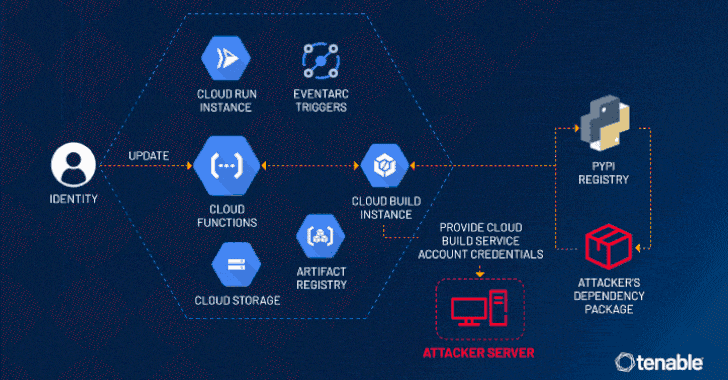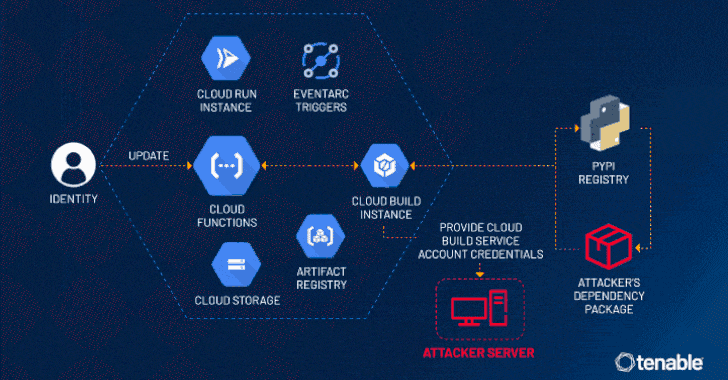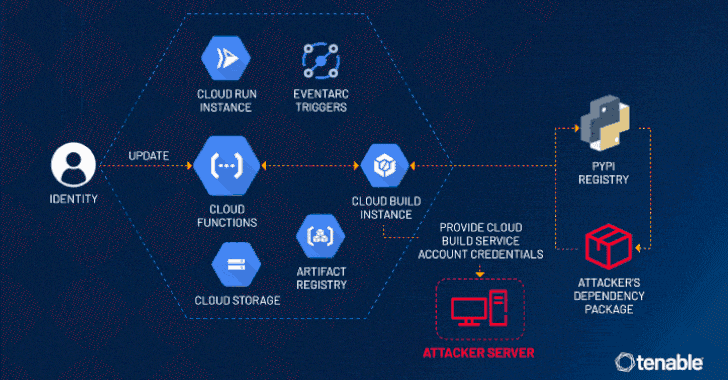









{kind=link}
{kind=link}
{kind=link}